

DEMO
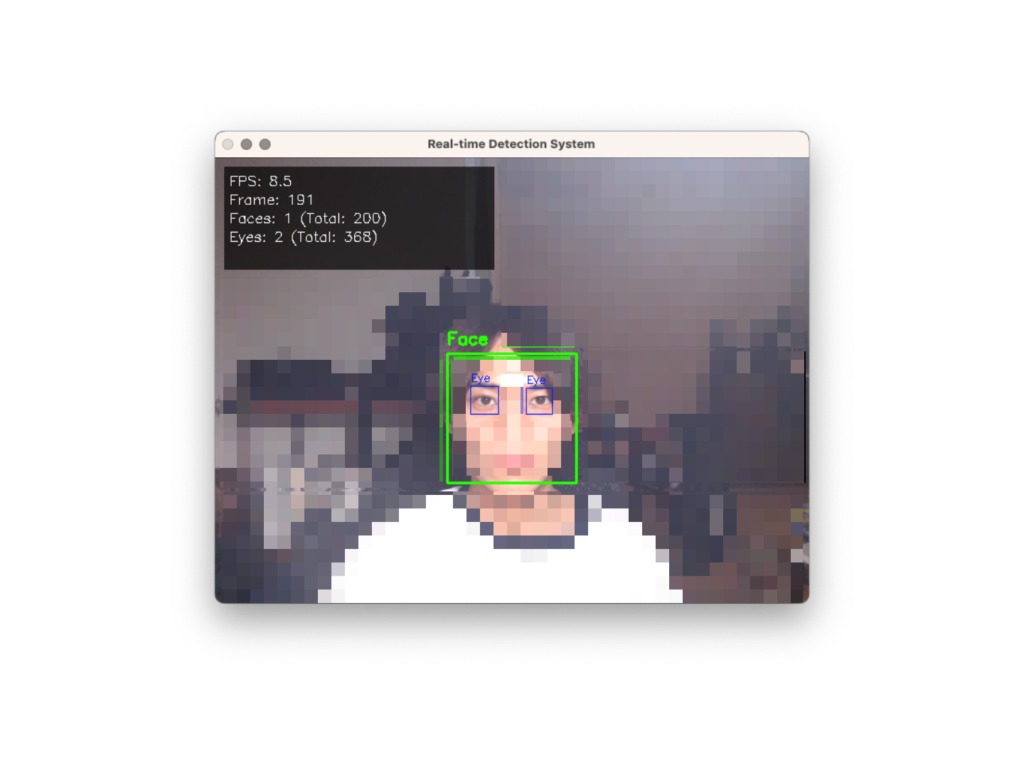
完成したシステムでは、Webカメラの映像がリアルタイムで表示され、検出された顔が緑色の矩形、目が青色の矩形で囲まれます。画面左上には現在のFPS、処理フレーム数、検出した顔と目の総数がリアルタイムで表示されます。システムは複数のカメラを自動検索し、利用可能なカメラを自動選択します。メガネをかけた人でも目の検出が可能で、’q’キーで安全に終了できます。プログラム終了時には総実行時間、平均FPS、検出率などの詳細な統計情報が表示されます。Haar特徴量ベースのカスケード分類器により30FPS程度のリアルタイム処理を実現し、検出パラメータの最適化により誤検出を抑えた安定した性能を提供します。
プロジェクト概要
前提条件
- Pythonプログラミングの基本的な知識(変数、関数、クラスの概念)
- VSCodeエディタの基本操作ができること
- ターミナル(コマンドライン)の基本的な使用経験
- Gitとバージョン管理の基礎知識
- Webカメラが使用可能な環境
開発環境
- Python 3.7以上
- VSCode(Visual Studio Code)
- Webカメラ(内蔵またはUSB接続)
- Git(バージョン管理システム)
- GitHubアカウント
- opencv-python
プロジェクト内容
このプロジェクトでは、OpenCVライブラリとカスケード分類器を使用して、Webカメラからリアルタイムで顔と目を検出するコンピュータビジョンシステムを構築します。初心者でも段階的に学習できるよう、基本的な環境設定から高度な検出機能まで、6つのステップに分けて実装していきます。
プロジェクトの核となるのは、Haar特徴量ベースのカスケード分類器による機械学習検出技術です。事前に学習された分類器モデルを活用することで、複雑な機械学習の知識がなくても高精度な物体検出システムを開発できます。
検出処理においては、ROI(関心領域)技術を使用して効率的な検出を行い、顔の検出後にその領域内で目を検出する階層的なアプローチを実装します。メガネをかけた人にも対応できる特別な分類器も組み込み、より実用的なシステムとします。さらに、リアルタイムでのFPS計測や検出統計の表示機能も実装し、システムの性能を可視化できます。
最終的に、完成したプロジェクトをGitHubにアップロードし、ポートフォリオとして活用できる形にします。適切なドキュメント(README.md)の作成や、.gitignoreファイルの設定など、実際の開発現場で必要とされる技術も学習できます。
実装内容
- Webカメラの自動検索と初期化システム
- 仮想環境の構築と依存関係管理(requirements.txt)
- カスケード分類器の読み込みと設定
- リアルタイム顔検出とROI範囲での目検出
- メガネ対応目検出機能の実装
- FPS計測とリアルタイム統計表示システム
- 検出結果の視覚的フィードバック機能
- エラーハンドリングと安全なリソース管理
- GitHubでのバージョン管理とポートフォリオ公開
得られるスキル
- OpenCVライブラリ(コンピュータビジョンと画像処理の基本操作)
- カスケード分類器(機械学習ベースの物体検出技術)
- リアルタイム映像処理(Webカメラからの連続フレーム処理と最適化)
- FPS計測とパフォーマンス最適化(システム性能の測定と改善手法)
得られる経験
- Webカメラからのリアルタイム映像取得と処理経験
- 機械学習モデル(分類器)の実装と活用経験
- コンピュータビジョン分野での実践的な開発経験
得られる成果物
- 完全に動作するリアルタイム顔・目検出システム
- GitHubでのポートフォリオとして活用可能なプロジェクト
- 完全なPythonソースコード
このプロジェクトから応用できること
- 入退室管理システムの基盤開発(OpenCVとカスケード分類器を使用して顔認識機能を実装)
- Web会議での自動フォーカス機能の実装(リアルタイム顔検出技術を活用してカメラ制御)
- 防犯カメラシステムの人物検出機能(カスケード分類器による検出技術を応用)
- アプリの顔認証機能の基礎実装(OpenCVの検出技術を基盤とした認証システム)
- 写真の自動分類システムの開発(物体検出技術を活用した画像整理)
Step1:開発環境の準備とプロジェクト構造の作成
このステップでは、リアルタイム顔認識Webカメラアプリプロジェクトを始めるための開発環境を整備し、必要なファイル構造を作成していきます。プログラミングを始める前の準備段階として、とても重要な作業になります。
※Step1の内容がわからない際は、下記記事にGitHubとVSCodeの連携について詳細を記載しているためご参照ください。

GitHubリポジトリの作成
まず最初に、プロジェクト専用のGitHubリポジトリを作成しましょう。
- GitHubの公式サイトにアクセスし、自分のアカウントでログインします
- 画面右上の「+」アイコンをクリックし、ドロップダウンメニューから「New repository」を選択します
- 新しいリポジトリの作成ページで、以下の情報を入力します
リポジトリの設定
- Repository name 「realtime-face-detection」と入力
- Description 「OpenCVを使用したリアルタイム顔・目検出Webカメラアプリケーション」と入力
- Visibility 「Public」を選択(ポートフォリオとして公開するため)
- Initialize this repository with
- 「Add a README file」にチェックを入れる
- 「Add .gitignore」で「Python」を選択
- 「Choose a license」は「None」のままにする
- 「Create repository」ボタンをクリックしてリポジトリを作成します
プロジェクトフォルダの作成
次に、プロジェクトを管理するための親フォルダを作成しましょう。
Windows・macOS共通
- デスクトップや任意の場所に新しいフォルダを作成します
- フォルダ名は任意ですが、ここでは例として「PythonPortfolio」に設定します
この親フォルダが、今後のプロジェクト全体を管理するルートディレクトリとなります。複数のプロジェクトを整理して管理するために作成しておくと便利です。
VSCodeでプロジェクトを開く
作成したGitHubリポジトリをローカルにクローンして開きましょう。
- VSCodeを起動します
- 左側のアクティビティバーからソース管理アイコン(分岐のようなアイコン)をクリックします
- 「リポジトリの複製」ボタンをクリックします
- 「GitHubから複製」を選択します
- 先ほど作成した「realtime-face-detection」リポジトリを選択します
- リポジトリ宛先として先ほど作成した親フォルダを選択します
- 「クローンしたリポジトリを開きますか」というウィンドウが表示されたら「開く」をクリックします
VSCodeの左側にエクスプローラーパネルが表示され、現在のプロジェクトフォルダの中身が確認できるようになります。
仮想環境の作成とアクティベート
Python開発において仮想環境は非常に重要です。仮想環境とは、プロジェクトごとに独立したPython実行環境を作成する仕組みのことです。これにより、プロジェクト間でのライブラリの競合を防ぎ、クリーンな開発環境を維持できます。
詳しくは下記記事をご参照ください。
Windows環境での仮想環境作成
- VSCodeの上部メニューから「ターミナル」→「新しいターミナル」を選択
- 以下のコマンドで仮想環境を作成します
python -m venv myenv- 仮想環境をアクティベートします
myenv\Scripts\activatemacOS環境での仮想環境作成
- VSCodeの上部メニューから「ターミナル」→「新しいターミナル」を選択
- 以下のコマンドで仮想環境を作成します
python3 -m venv myenv- 仮想環境をアクティベートします
source myenv/bin/activate重要なポイント
- 仮想環境名は「myenv」として作成
- ターミナルの行頭に「(myenv)」と表示されることを確認
- この表示があることで、仮想環境が正常にアクティベートされていることがわかります
プロジェクトファイル構造の作成
次に、今回のリアルタイム顔認識プロジェクトに必要なフォルダとファイルを作成していきます。VSCodeのエクスプローラーパネルを使用してファイルを作成しましょう。
ソースコード用フォルダの作成
- VSCodeの左側エクスプローラーパネルで「新しいフォルダ」アイコン(フォルダの絵とプラスのマークがあるアイコン)をクリック
- フォルダ名を「src」として作成
この「src」フォルダはsource code(ソースコード)の略で、プログラムのメインファイルを格納するための専用フォルダです。プロジェクトの整理整頓において重要な役割を果たします。
分類器用フォルダの作成
- 同じくエクスプローラーパネルで「新しいフォルダ」アイコンをクリック
- フォルダ名を「classifiers」として作成
「classifiers」フォルダは、カスケード分類器のXMLファイルを保管するためのフォルダです。今回のプロジェクトでは、顔と目を検出するための学習済みモデルファイルがここに保存されます。
メインプログラムファイルの作成
- 先ほど作成した「src」フォルダをクリックして選択
- 「新しいファイル」アイコン(ファイルの絵とプラスのマークがあるアイコン)をクリック
- ファイル名を「webcam_detector.py」として作成
この「webcam_detector.py」ファイルが、今回のリアルタイム顔・目検出機能を実装するメインプログラムとなります。.py拡張子はPythonスクリプトファイルであることを示しており、実行可能なプログラムコードを記述するために使用します。
カスケード分類器ファイルのダウンロードと配置
今回のプロジェクトで使用する顔・目検出用のカスケード分類器XMLファイルをダウンロードして配置します。これらのファイルは、OpenCVが提供する学習済みのモデルです。
必要なカスケード分類器ファイル
以下の3つのXMLファイルをダウンロードしてください。
1. haarcascade_frontalface_default.xml
- 対象物体: 正面を向いた顔
- 用途: 人間の顔を正面から検出するための分類器
- 特徴: 最も基本的で精度の高い顔検出モデル
2. haarcascade_eye.xml
- 対象物体: 目
- 用途: 人間の目を検出するための分類器
- 特徴: 顔検出と組み合わせることで、より詳細な顔分析が可能
3. haarcascade_eye_tree_eyeglasses.xml
- 対象物体: メガネをかけた目
- 用途: メガネを着用している人の目も検出できる分類器
- 特徴: 通常の目検出では困難なメガネ着用時にも対応
ダウンロード手順
以下のリンクから各XMLファイルをダウンロードしてください。
ファイルの配置
ダウンロードした3つのXMLファイルを、プロジェクトの「classifiers」フォルダ内に配置してください。VSCodeのエクスプローラーパネルで、ダウンロードしたファイルを「classifiers」フォルダにドラッグ&ドロップすることで簡単に配置できます。
カスケード分類器とは、機械学習を用いて特定の物体(今回は顔や目)を検出するための学習済みモデルです。XML(eXtensible Markup Language)形式で保存されており、OpenCVライブラリが提供する標準的な検出アルゴリズムです。これらのファイルには、何千もの画像から学習した特徴パターンが含まれており、リアルタイムでの高精度な物体検出を可能にします。
依存関係管理ファイルの作成
- プロジェクトのルートフォルダ(realtime-face-detection)をクリックして選択
- 「新しいファイル」アイコンをクリック
- ファイル名を「requirements.txt」として作成
requirements.txtファイルは、Pythonプロジェクトで使用する外部ライブラリとそのバージョンを記録するための重要なファイルです。これにより、他の開発者や本番環境でも同じライブラリ環境を再現できます。
requirements.txtの内容設定
作成した「requirements.txt」ファイルをVSCodeで開き、以下の内容を記述してください。
opencv-python==4.11.0.86今回のプロジェクトでは、opencv-pythonというライブラリを使用します。
- opencv-python コンピュータビジョンと画像処理のための強力なライブラリです。Webカメラからの映像キャプチャ、画像の前処理、物体検出など、今回のプロジェクトで必要な全ての機能を提供します。顔や目の検出機能も含まれており、リアルタイム映像処理において業界標準となっているツールです
プロジェクト構造の確認
この時点で、VSCodeのエクスプローラーパネルには以下のような構造が表示されているはずです。
realtime-face-detection/
├── myenv/ # 仮想環境フォルダ
├── src/
│ └── webcam_detector.py # メインプログラムファイル
├── classifiers/
│ ├── haarcascade_frontalface_default.xml # 正面顔検出用分類器
│ ├── haarcascade_eye.xml # 目検出用分類器
│ └── haarcascade_eye_tree_eyeglasses.xml # メガネ対応目検出用分類器
├── requirements.txt # 依存関係管理ファイル
├── README.md # プロジェクト説明書(GitHub作成時に自動生成)
└── .gitignore # Git除外設定ファイル(GitHub作成時に自動生成)
この基本構造が、今回のリアルタイム顔認識プロジェクトの基盤となります。GitHubで作成したリポジトリをクローンしたため、README.mdと.gitignoreファイルが最初から含まれています。
仮想環境が正常にアクティベートされていることを再度確認し(ターミナルに「(myenv)」が表示されている状態)、次のステップに進む準備を整えましょう。
ライブラリのインストール
仮想環境がアクティベートされている状態で、VSCodeのターミナルから以下のコマンドを実行します。
pip install -r requirements.txtこのコマンドにより、requirements.txtに記載されたopencv-pythonライブラリがインストールされます。インストール処理には数分程度かかる場合がありますので、しばらくお待ちください。
インストールが完了すると、ターミナルに「Successfully installed opencv-python-4.11.0.86」のようなメッセージが表示され、プロジェクトの環境準備が完了します。
Step2:基本Webカメラキャプチャ機能の実装
このステップでは、OpenCVライブラリを使用してWebカメラからの映像を取得し、リアルタイムで表示する基本機能を実装します。この機能が、後の顔検出機能の土台となる重要な部分です。
WebcamDetectorクラスの作成
まず、Webカメラ検出機能をまとめて管理するクラスを作成します。このクラスの中に、今後必要な機能をすべてdef文(関数)として実装していきます。
VSCodeで「src/webcam_detector.py」ファイルを開き、以下のコードを記述してください。
# 必要なライブラリをインポート
import cv2 as cv # OpenCVライブラリ(画像・動画処理用)
import os # ファイルパス操作用
import time # 時間計測用
class WebcamDetector:
"""
Webカメラを使用したリアルタイム検出システムのメインクラス
"""
def __init__(self):
"""
WebcamDetectorクラスの初期化メソッド
オブジェクト作成時に自動で呼ばれる
"""
# カメラ関連の初期値設定
self.camera = None # Webカメラオブジェクト格納用
self.is_running = False # システム動作状態の管理フラグ
self.window_name = "Real-time Detection System" # 表示ウィンドウ名
self.camera_index = 0 # 使用カメラの番号(0が標準)__init__メソッドはクラスの初期化を行う特別な関数です。ここでWebカメラオブジェクトの初期値を設定し、動作状態を管理するためのフラグを用意します。
カメラアクセス許可確認機能の実装
システムでカメラへのアクセス許可を確認するメソッドを実装します。
def check_camera_permission(self):
"""
利用可能なカメラを検索して接続テストを行うメソッド
複数のカメラがある場合も自動で最適なものを選択
Returns:
int: 使用可能なカメラ番号、見つからない場合は-1
"""
print("利用可能なカメラを検索しています...")
# カメラ番号0〜3まで順番にテスト
for index in range(4):
print(f"カメラ番号 {index} をテスト中...")
# テスト用カメラオブジェクトを作成
test_camera = cv.VideoCapture(index)
# カメラが開けるかチェック
if test_camera.isOpened():
# 実際に画像が取得できるかテスト
ret, frame = test_camera.read()
# テスト完了後はリソースを解放
test_camera.release()
# 画像取得成功なら使用可能
if ret and frame is not None:
print(f"カメラ番号 {index} が利用可能です")
return index
else:
print(f"カメラ番号 {index} は画像取得に失敗")
else:
print(f"カメラ番号 {index} にアクセスできません")
# 利用可能なカメラが見つからない場合
print("利用可能なカメラが見つかりませんでした")
return -1このメソッドは複数のカメラインデックスを順番に試行し、実際にアクセス可能なカメラを特定します。
Webカメラ初期化機能の実装
次に、クラス内にsetup_cameraメソッドを実装します。
def setup_camera(self):
"""
Webカメラの初期化と各種設定を行うメソッド
カメラアクセス確認と詳細設定を一括処理
Returns:
bool: 初期化成功でTrue、失敗でFalse
"""
# まずカメラアクセス許可状況を確認
available_camera = self.check_camera_permission()
# 利用可能カメラが見つからない場合の対処
if available_camera == -1:
print("\n=== カメラアクセスのトラブルシューティング ===")
print("1. カメラが他のアプリで使用中でないか確認")
print("2. macOSの場合 システム環境設定 > セキュリティとプライバシー > カメラ")
print("3. Windowsの場合 設定 > プライバシー > カメラ")
print("4. ターミナルやVSCodeにカメラ許可を与える")
return False
# 使用するカメラ番号を記録
self.camera_index = available_camera
try:
# VideoCapture オブジェクトでカメラに接続
self.camera = cv.VideoCapture(self.camera_index)
# カメラが正常に開かれているか最終確認
if not self.camera.isOpened():
print("エラー Webカメラの初期化に失敗しました")
return False
# カメラの安定化待機(重要)
time.sleep(1)
# 解像度設定(640x480ピクセル)
self.camera.set(cv.CAP_PROP_FRAME_WIDTH, 640)
self.camera.set(cv.CAP_PROP_FRAME_HEIGHT, 480)
# フレームレート設定(1秒30枚)
self.camera.set(cv.CAP_PROP_FPS, 30)
# バッファサイズ調整でリアルタイム性向上
self.camera.set(cv.CAP_PROP_BUFFERSIZE, 1)
print(f"カメラ番号 {self.camera_index} で初期化完了")
return True
except Exception as e:
print(f"カメラ初期化中にエラー発生 {e}")
return Falseこのメソッドはクラス内で定義されているため、selfキーワードを使用してクラスの属性にアクセスできます。カメラアクセス許可の確認も含むため、システムレベルでの問題も検出できます。
ビデオキャプチャについて
ビデオキャプチャは、Webカメラやビデオファイルから連続した画像(フレーム)を取得する機能です。OpenCVのVideoCaptureクラスを使用することで、リアルタイムでカメラからの映像データを取得できます。この機能により、静止画ではなく動画として映像を処理することが可能になります。
フレーム取得機能の実装
WebcamDetectorクラス内に、カメラからフレームを取得するメソッドを追加します。
def capture_frame(self):
"""
Webカメラから1枚の画像(フレーム)を取得するメソッド
エラー対策として複数回の取得試行を実装
Returns:
tuple: (成功フラグ, 画像データ) の組み合わせ
"""
# カメラが初期化されているかチェック
if self.camera is None:
print("エラー カメラが初期化されていません")
return False, None
# 最大3回まで取得を試行
for attempt in range(3):
# カメラから1フレーム読み取り
success, frame = self.camera.read()
# 取得成功かつ画像データが存在するかチェック
if success and frame is not None:
# 画像データが空でないか最終確認
if frame.size > 0:
return True, frame
else:
print(f"警告 空の画像を取得 (試行 {attempt + 1}/3)")
else:
print(f"警告 画像取得に失敗 (試行 {attempt + 1}/3)")
# 次の試行前に少し待機
time.sleep(0.1)
# 全試行失敗の場合
return False, Noneこのメソッドは、Webカメラからフレームと呼ばれる1枚の画像を取得します。フレームとは、動画を構成する個々の静止画のことで、これらが連続して表示されることで動画として認識されます。
フレーム表示機能の実装
取得したフレームを画面に表示するメソッドをクラス内に追加します。
def display_frame(self, frame):
"""
取得した画像をウィンドウに表示するメソッド
ウィンドウサイズ調整も自動で実行
Args:
frame: 表示したい画像データ(numpy配列形式)
"""
# 画像データが存在するかチェック
if frame is None:
return
# ウィンドウサイズを画像に合わせて自動調整
cv.namedWindow(self.window_name, cv.WINDOW_AUTOSIZE)
# 指定したウィンドウに画像を表示
cv.imshow(self.window_name, frame)このメソッドでは、cv.imshow()関数を使用してフレームを表示します。imshowは「image show」の略で、画像データを指定されたウィンドウに表示する機能です。
キー入力処理機能の実装
ユーザーのキー入力を検出し、プログラムの終了を制御するメソッドを追加します。
def check_exit_key(self):
"""
キーボード入力を監視して終了指示を検出するメソッド
Returns:
bool: 終了キー押下でTrue、それ以外でFalse
"""
# 30ミリ秒間キー入力を待機(フレームレート調整も兼ねる)
key = cv.waitKey(30) & 0xFF
# 'q'キー、'Q'キー、ESCキー(番号27)のいずれかが押されたかチェック
if key == ord('q') or key == ord('Q') or key == 27:
return True
# 上記以外のキーまたはキー入力なしの場合
return Falsecv.waitKey()は、指定されたミリ秒数だけキーボード入力を待機する関数です。& 0xFFは、キーコードの下位8ビットのみを取得するビット演算で、システム間の互換性を保つために使用されます。待機時間を30ミリ秒に設定することで、適切なフレームレートを維持しながらキー入力を確実に検出できます。
ウィンドウフォーカス管理機能の実装
OpenCVウィンドウにフォーカスを当てるメソッドを追加します。
def ensure_window_focus(self):
"""
OpenCVウィンドウを最前面に表示してキー入力を受けやすくするメソッド
特にmacOSでキー入力が効かない問題の対策
"""
# ウィンドウを一時的に最前面に移動
cv.setWindowProperty(self.window_name, cv.WND_PROP_TOPMOST, 1)
# すぐに最前面設定を解除(通常状態に戻す)
cv.setWindowProperty(self.window_name, cv.WND_PROP_TOPMOST, 0)このメソッドは、OpenCVのウィンドウを最前面に表示してキー入力を受け付けやすくします。特にmacOSやLinuxでキー入力が効かない場合に有効です。
メインループ機能の実装
カメラの映像を連続して表示するメインループメソッドを実装します。
def run_detection(self):
"""
リアルタイム映像表示のメインループ実行メソッド
カメラ初期化から終了まで全体制御を行う
"""
# Step1 カメラの初期化処理
if not self.setup_camera():
print("カメラ初期化失敗のため終了します")
return
# Step2 システム動作開始の準備
self.is_running = True
print("検出システムを開始します")
print("終了するには 'q' キーまたはESCキーを押してください")
print("※ウィンドウをクリックしてからキーを押してください")
# カウンタ変数の初期化
frame_count = 0 # 処理したフレーム数
error_count = 0 # 連続エラー数
max_errors = 10 # 許可する最大連続エラー数
try:
# Step3 メインループ開始
while self.is_running:
# フレーム取得処理
success, frame = self.capture_frame()
# フレーム取得失敗の場合
if not success:
error_count += 1
print(f"フレーム取得エラー ({error_count}/{max_errors})")
# 連続エラーが上限に達した場合は終了
if error_count >= max_errors:
print("連続エラー上限に達したため終了します")
break
# 次のループに進む
continue
# フレーム取得成功時の処理
error_count = 0 # エラーカウントをリセット
frame_count += 1 # 成功フレーム数をカウント
# 取得したフレームを画面に表示
self.display_frame(frame)
# 初回表示時のみウィンドウフォーカス設定
if frame_count == 1:
self.ensure_window_focus()
# 終了キー入力チェック
if self.check_exit_key():
print("終了キーが検出されました")
self.is_running = False
break
# Ctrl+Cでの強制終了をキャッチ
except KeyboardInterrupt:
print("\nプログラムが中断されました")
# 正常・異常終了に関わらず実行される処理
finally:
print(f"総フレーム数 {frame_count}")
# リソース解放処理を実行
self.cleanup()このメソッドは、while文を使用して無限ループを作成し、カメラからフレームを取得→表示→キー入力チェックのサイクルを繰り返します。エラーハンドリングも含まれており、連続エラー時の自動終了機能もあります。
リソース解放機能の実装
プログラム終了時にカメラとウィンドウを適切に解放するメソッドを追加します。
def cleanup(self):
"""
プログラム終了時のリソース解放処理
メモリリークやカメラ占有を防ぐ重要な処理
"""
print("リソースを解放しています...")
# カメラリソースの解放処理
if self.camera is not None:
# カメラ接続を終了
self.camera.release()
print("カメラリソースを解放しました")
# すべてのOpenCVウィンドウを閉じる
cv.destroyAllWindows()
# ウィンドウが完全に閉じるまで待機
for i in range(5):
cv.waitKey(1)
print("ウィンドウを閉じました")
print("クリーンアップが完了しました")リソースの解放とは、プログラムが使用していたメモリやハードウェア(Webカメラなど)を適切に開放し、他のプログラムが使用できる状態に戻すことです。これを行わないと、カメラが他のアプリケーションで使用できなくなったり、メモリリークが発生する可能性があります。
メイン実行部分の実装
main関数を作成して、WebcamDetectorクラスを使用する実行部分を実装します。
def main():
"""
プログラムのメイン実行関数
WebcamDetectorオブジェクトを作成してシステム開始
"""
# システム開始のお知らせ
print("=== リアルタイム検出システム ===")
print("Webカメラを使用した検出システムを開始します")
print()
# WebcamDetectorのインスタンス(実体)を作成
detector = WebcamDetector()
# 検出システムのメイン処理を開始
detector.run_detection()
# システム終了のお知らせ
print("プログラムを終了します")
# スクリプトが直接実行された場合のみmain関数を呼び出し
if __name__ == "__main__":
main()
if name == “main”:は、このスクリプトが直接実行された場合のみmain関数を実行するPythonの構文です。他のモジュールからインポートされた場合は実行されません。
動作テスト実行
VSCodeのターミナルでプログラムを実行してテストします。仮想環境がアクティベートされていることを確認してから実行してください。
Windows環境の場合
python src/webcam_detector.pymacOS環境の場合
python3 src/webcam_detector.pyプログラムが正常に動作すると、利用可能なカメラの検索が始まり、Webカメラからの映像がリアルタイムでウィンドウに表示されます。ウィンドウをクリックしてフォーカスを当ててから、’q’キーまたはESCキーを押すことでプログラムを終了できます。
GUI画面(実際のGUIにはモザイクはありません)

Step3:カスケード分類器の設定と基本構造の作成
このステップでは、カスケード分類器を読み込み、顔と目の検出に必要な基本構造を作成します。カスケード分類器は機械学習で訓練されたXMLファイルで、特定の物体を画像から検出するためのパターンが記録されています。
カスケード分類器について
カスケード分類器とは、機械学習のアルゴリズムの一種で、何千もの画像から学習したパターンを使って物体を検出する仕組みです。カスケードという名前は、複数の段階(カスケード)を経て検出を行うことから来ています。各段階で「これは顔ではない」と判断された領域は早期に除外され、計算効率を向上させています。
WebcamDetectorクラスの拡張
既存のWebcamDetectorクラスに、カスケード分類器の読み込み機能を追加します。「src/webcam_detector.py」ファイルを開き、以下の部分を追加・変更してください。
まず、クラスの初期化メソッドに分類器関連の属性を追加します。
def __init__(self):
"""
WebcamDetectorクラスの初期化メソッド
オブジェクト作成時に自動で呼ばれる
"""
# カメラ関連の初期値設定
self.camera = None # Webカメラオブジェクト格納用
self.is_running = False # システム動作状態の管理フラグ
self.window_name = "Real-time Detection System" # 表示ウィンドウ名
self.camera_index = 0 # 使用カメラの番号(0が標準)
# 以下を追加 カスケード分類器関連の初期値設定
self.face_cascade = None # 顔検出用分類器オブジェクト
self.eye_cascade = None # 目検出用分類器オブジェクト
self.eye_glasses_cascade = None # メガネ対応目検出用分類器オブジェクト
self.classifiers_loaded = False # 分類器読み込み完了フラグ新しく追加した属性は、各種カスケード分類器オブジェクトと読み込み状態を管理するためのものです。
分類器ファイル存在確認機能の実装
カスケード分類器のXMLファイルが正しく配置されているかを確認するメソッドを追加します。
def check_classifier_files(self):
"""
カスケード分類器XMLファイルの存在確認メソッド
プロジェクトフォルダ内の分類器ファイルを自動検索
Returns:
dict: 各分類器ファイルのパス情報を格納した辞書
"""
print("カスケード分類器ファイルの存在確認を開始します...")
# 現在のファイルから2階層上がプロジェクトルート
base_dir = os.path.dirname(os.path.dirname(__file__))
# classifiersフォルダのパスを作成
classifiers_dir = os.path.join(base_dir, 'classifiers')
# 必要な分類器ファイル名とパスの定義
classifier_files = {
'face': os.path.join(classifiers_dir, 'haarcascade_frontalface_default.xml'),
'eye': os.path.join(classifiers_dir, 'haarcascade_eye.xml'),
'eye_glasses': os.path.join(classifiers_dir, 'haarcascade_eye_tree_eyeglasses.xml')
}
# ファイル存在状況を記録する辞書
file_status = {}
# 各ファイルの存在確認ループ
for classifier_type, file_path in classifier_files.items():
# ファイルが存在するかチェック
if os.path.exists(file_path):
print(f"✓ {classifier_type} 分類器ファイルを発見 {os.path.basename(file_path)}")
file_status[classifier_type] = file_path # パスを記録
else:
print(f"✗ {classifier_type} 分類器ファイルが見つかりません {file_path}")
file_status[classifier_type] = None # 見つからない場合はNone
return file_statusこのメソッドは、os.path.exists()を使用してXMLファイルの存在を確認し、結果を辞書形式で返します。os.path.dirname()は、現在のファイルがあるディレクトリを取得する関数です。
カスケード分類器読み込み機能の実装
実際にカスケード分類器をメモリに読み込むメソッドを追加します。
def load_cascades(self):
"""
カスケード分類器をメモリに読み込んで使用準備するメソッド
3つの分類器(顔、目、メガネ対応目)を順次読み込み
Returns:
bool: 必須分類器の読み込み成功でTrue、失敗でFalse
"""
print("カスケード分類器の読み込みを開始します...")
# まずファイル存在確認を実行
file_status = self.check_classifier_files()
try:
# 顔検出用分類器の読み込み(必須)
if file_status['face']:
# XMLファイルから分類器オブジェクトを作成
self.face_cascade = cv.CascadeClassifier(file_status['face'])
# 読み込み成功確認(空のオブジェクトでないかチェック)
if self.face_cascade.empty():
print("エラー 顔検出分類器の読み込みに失敗しました")
return False
print("顔検出分類器の読み込み完了")
else:
print("エラー 顔検出分類器ファイルが見つかりません")
return False
# 目検出用分類器の読み込み(必須)
if file_status['eye']:
# XMLファイルから分類器オブジェクトを作成
self.eye_cascade = cv.CascadeClassifier(file_status['eye'])
# 読み込み成功確認
if self.eye_cascade.empty():
print("エラー 目検出分類器の読み込みに失敗しました")
return False
print("目検出分類器の読み込み完了")
else:
print("エラー 目検出分類器ファイルが見つかりません")
return False
# メガネ対応目検出用分類器の読み込み(オプション)
if file_status['eye_glasses']:
# XMLファイルから分類器オブジェクトを作成
self.eye_glasses_cascade = cv.CascadeClassifier(file_status['eye_glasses'])
# 読み込み失敗でもシステム継続(オプション機能のため)
if self.eye_glasses_cascade.empty():
print("警告 メガネ対応目検出分類器の読み込みに失敗(オプション機能)")
self.eye_glasses_cascade = None
else:
print("メガネ対応目検出分類器の読み込み完了")
else:
print("警告 メガネ対応目検出分類器ファイルが見つかりません(オプション機能)")
self.eye_glasses_cascade = None
# 読み込み完了フラグを設定
self.classifiers_loaded = True
print("カスケード分類器の読み込みが完了しました")
return True
except Exception as e:
print(f"分類器読み込み中にエラーが発生しました {e}")
return Falsecv.CascadeClassifier()は、XMLファイルからカスケード分類器を読み込むOpenCVの関数です。empty()メソッドで、分類器が正しく読み込まれたかを確認できます。
XMLファイルについて
XML(eXtensible Markup Language)は、データを構造化して記述するためのマークアップ言語です。OpenCVのカスケード分類器では、機械学習で学習したパターン情報がXML形式で保存されています。これらのファイルには、顔や目の特徴的なパターン(エッジ、輪郭、明暗の変化など)が数値データとして記録されており、新しい画像に対してこれらのパターンと照合することで物体検出を行います。
グレースケール変換機能の実装
物体検出を高速化するために、カラー画像をグレースケールに変換する機能を追加します。
def convert_to_grayscale(self, frame):
"""
カラー画像をグレースケール(白黒)に変換するメソッド
検出処理の高速化と精度向上のため
Args:
frame: 変換元のカラー画像(BGR形式)
Returns:
numpy.ndarray: グレースケール変換後の画像データ
"""
# 入力画像の存在確認
if frame is None:
return None
# BGRカラーからグレースケールに変換
gray_frame = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
return gray_frameグレースケール変換は、カラー画像を白黒画像に変換する処理です。cv.cvtColor()関数でcv.COLOR_BGR2GRAYを指定することで、BGR(Blue-Green-Red)カラー形式からグレースケールに変換されます。グレースケール画像は色情報がないため、処理が軽くなり、カスケード分類器による検出も高速化されます。
基本検出準備機能の実装
検出処理の前準備を行うメソッドを追加します。
def prepare_detection(self, frame):
"""
検出処理実行前の準備作業メソッド
画像品質チェックとグレースケール変換を実行
Args:
frame: 処理対象の元画像
Returns:
tuple: (元画像, グレースケール画像) の組み合わせ
エラー時は (None, None)
"""
# 入力画像の存在確認
if frame is None:
return None, None
# 画像サイズの取得と最小サイズチェック
height, width = frame.shape[:2]
if width < 100 or height < 100:
print("警告 画像サイズが小さすぎます")
return None, None
# カラー画像をグレースケールに変換
gray_frame = self.convert_to_grayscale(frame)
# グレースケール変換の成功確認
if gray_frame is None:
print("エラー グレースケール変換に失敗しました")
return None, None
# 元画像とグレースケール画像の両方を返す
return frame, gray_frameこのメソッドは、検出処理に適した画像かをチェックし、グレースケール変換を行います。画像サイズが小さすぎる場合は処理をスキップします。
メインループの更新
既存のrun_detectionメソッドを更新して、カスケード分類器の読み込みを含めます。
def run_detection(self):
"""
リアルタイム検出のメインループ実行メソッド
カメラ初期化から分類器読み込み、検出処理まで全体制御
"""
# Step1 カメラの初期化処理
if not self.setup_camera():
print("カメラ初期化失敗のため終了します")
return
# 以下を追加 Step2 カスケード分類器の読み込み処理
if not self.load_cascades():
print("カスケード分類器読み込み失敗のため終了します")
# カメラリソース解放してから終了
self.cleanup()
return
# Step3 システム動作開始の準備
self.is_running = True
print("検出システムを開始します")
print("終了するには 'q' キーまたはESCキーを押してください")
print("※ウィンドウをクリックしてからキーを押してください")
# カウンタ変数の初期化
frame_count = 0 # 処理したフレーム数
error_count = 0 # 連続エラー数
max_errors = 10 # 許可する最大連続エラー数
try:
# Step4 メインループ開始
while self.is_running:
# フレーム取得処理
success, frame = self.capture_frame()
# フレーム取得失敗の場合
if not success:
error_count += 1
print(f"フレーム取得エラー ({error_count}/{max_errors})")
# 連続エラーが上限に達した場合は終了
if error_count >= max_errors:
print("連続エラー上限に達したため終了します")
break
# 次のループに進む
continue
# フレーム取得成功時の処理
error_count = 0 # エラーカウントをリセット
frame_count += 1 # 成功フレーム数をカウント
# 以下を追加 Step5 検出前準備処理
processed_frame, gray_frame = self.prepare_detection(frame)
# 準備処理失敗時はスキップ
if processed_frame is None:
continue
# 準備完了した画像を表示(まだ検出結果は描画していない)
self.display_frame(processed_frame)
# 初回表示時のみウィンドウフォーカス設定
if frame_count == 1:
self.ensure_window_focus()
# 終了キー入力チェック
if self.check_exit_key():
print("終了キーが検出されました")
self.is_running = False
break
# Ctrl+Cでの強制終了をキャッチ
except KeyboardInterrupt:
print("\nプログラムが中断されました")
# 正常・異常終了に関わらず実行される処理
finally:
print(f"総フレーム数 {frame_count}")
# リソース解放処理を実行
self.cleanup()メインループに分類器の読み込み処理と、検出前準備処理を追加しました。まだ実際の検出は行いませんが、基本構造を整えています。
メイン実行部分の更新
main関数で、分類器関連の説明を追加します。
def main():
"""
プログラムのメイン実行関数
WebcamDetectorオブジェクトを作成してシステム開始
"""
# システム開始のお知らせ
print("=== リアルタイム検出システム ===")
print("Webカメラを使用した検出システムを開始します")
print("顔・目検出用のカスケード分類器を読み込みます")
print()
# WebcamDetectorのインスタンス(実体)を作成
detector = WebcamDetector()
# 検出システムのメイン処理を開始
detector.run_detection()
# システム終了のお知らせ
print("プログラムを終了します")
# スクリプトが直接実行された場合のみmain関数を呼び出し
if __name__ == "__main__":
main()動作テスト実行
VSCodeのターミナルでプログラムを実行してテストします。仮想環境がアクティベートされていることを確認してから実行してください。
Windows環境の場合
python src/webcam_detector.pymacOS環境の場合
python3 src/webcam_detector.pyプログラムが正常に動作すると、カスケード分類器ファイルの存在確認と読み込みが行われ、その後Webカメラからの映像が表示されます。現時点ではまだ顔や目の検出は行われませんが、分類器が正常に読み込まれることが確認できます。
出力 ターミナルの出力例
=== リアルタイム検出システム ===
Webカメラを使用した検出システムを開始します
顔・目検出用のカスケード分類器を読み込みます
利用可能なカメラを検索しています...
カメラインデックス 0 をテスト中...
カメラインデックス 0 はフレーム取得に失敗しました
カメラインデックス 1 をテスト中...
カメラインデックス 1 が利用可能です
カメラインデックス 1 で初期化が完了しました
カスケード分類器の読み込みを開始します...
カスケード分類器ファイルの存在確認を開始します...
✓ face 分類器ファイルが見つかりました: haarcascade_frontalface_default.xml
✓ eye 分類器ファイルが見つかりました: haarcascade_eye.xml
✓ eye_glasses 分類器ファイルが見つかりました: haarcascade_eye_tree_eyeglasses.xml
顔検出分類器の読み込み完了
目検出分類器の読み込み完了
メガネ対応目検出分類器の読み込み完了
カスケード分類器の読み込みが完了しました
検出システムを開始します
終了するには 'q' キーまたはESCキーを押してください
※ウィンドウをクリックしてからキーを押してくださいStep4:顔・目検出とリアルタイム表示の実装
このステップでは、読み込んだカスケード分類器を使用して実際に顔と目の検出を行い、検出結果を矩形で囲んでリアルタイム表示する機能を実装します。detectMultiScale関数を使用した物体検出の核心部分になります。
顔検出機能の実装
WebcamDetectorクラスに、顔を検出するメソッドを追加します。「src/webcam_detector.py」ファイルを開き、以下のメソッドを追加してください。
def detect_faces(self, gray_frame):
"""
グレースケール画像から顔を検出するメソッド
カスケード分類器を使用した顔領域の特定
Args:
gray_frame: グレースケール変換済みの画像データ
Returns:
numpy.ndarray: 検出された顔の座標情報配列 (x, y, width, height)
"""
# 入力画像と分類器の存在確認
if gray_frame is None or self.face_cascade is None:
return []
try:
# detectMultiScale関数で顔検出を実行
faces = self.face_cascade.detectMultiScale(
gray_frame, # 検索対象の画像データ
scaleFactor=1.1, # 画像縮小比率(1.1は10%ずつ縮小)
minNeighbors=5, # 検出に必要な近隣矩形数(誤検出防止)
minSize=(30, 30), # 検出する顔の最小サイズ(ピクセル)
maxSize=(300, 300) # 検出する顔の最大サイズ(ピクセル)
)
# 検出結果を配列で返す
return faces
except Exception as e:
print(f"顔検出中にエラーが発生しました {e}")
return []detectMultiScaleは、OpenCVのカスケード分類器で最も重要な関数です。scaleFactorは画像を段階的に縮小する比率、minNeighborsは誤検出を減らすためのパラメータ、minSize/maxSizeは検出対象のサイズ範囲を指定します。
目検出機能の実装
顔の領域内で目を検出するメソッドを追加します。
def detect_eyes(self, gray_frame, face_roi=None):
"""
グレースケール画像から目を検出するメソッド
顔領域指定時はその範囲内で効率的に検出
Args:
gray_frame: グレースケール変換済みの画像データ
face_roi: 顔領域の座標 (x, y, width, height)、Noneで画像全体検索
Returns:
numpy.ndarray: 検出された目の座標情報配列 (x, y, width, height)
"""
# 入力画像と分類器の存在確認
if gray_frame is None or self.eye_cascade is None:
return []
try:
# 検索範囲の設定処理
if face_roi is not None:
# 顔領域の座標とサイズを取得
x, y, w, h = face_roi
# 顔の上半分のみを目検索対象にする(目は顔の上部にあるため)
roi_gray = gray_frame[y:y + h//2, x:x + w]
# 元画像座標系への変換用のオフセット値
detection_area = (x, y)
else:
# 顔領域未指定時は画像全体を検索
roi_gray = gray_frame
detection_area = (0, 0)
# 目検出の実行
eyes = self.eye_cascade.detectMultiScale(
roi_gray,
scaleFactor=1.05, # 目は小さいのでより細かい縮小率
minNeighbors=3, # 顔より緩い条件で検出
minSize=(10, 10), # 目の最小サイズ
maxSize=(50, 50) # 目の最大サイズ
)
# 座標を元の画像座標系に変換
if face_roi is not None and len(eyes) > 0:
# x座標を元画像座標系に補正
eyes[:, 0] += detection_area[0]
# y座標を元画像座標系に補正
eyes[:, 1] += detection_area[1]
# 検出結果を返す
return eyes
except Exception as e:
print(f"目検出中にエラーが発生しました {e}")
return []このメソッドでは、ROI(Region of Interest)という概念を使用しています。ROIとは「関心領域」という意味で、画像の特定部分だけを処理対象にすることで、検出精度と処理速度を向上させる技術です。
メガネ対応目検出機能の実装
メガネをかけた人の目も検出できる機能を追加します。
def detect_eyes_with_glasses(self, gray_frame, face_roi=None):
"""
メガネ着用者に対応した目検出メソッド
通常の目検出で失敗した場合の補完機能
Args:
gray_frame: グレースケール変換済みの画像データ
face_roi: 顔領域の座標 (x, y, width, height)
Returns:
numpy.ndarray: 検出された目の座標情報配列 (x, y, width, height)
"""
# 入力画像とメガネ対応分類器の存在確認
if gray_frame is None or self.eye_glasses_cascade is None:
return []
try:
# 検索範囲の設定処理
if face_roi is not None:
# 顔領域の座標とサイズを取得
x, y, w, h = face_roi
# 顔の上半分でメガネ対応検出を実行
roi_gray = gray_frame[y:y + h//2, x:x + w]
# 元画像座標系への変換用のオフセット値
detection_area = (x, y)
else:
# 顔領域未指定時は画像全体を検索
roi_gray = gray_frame
detection_area = (0, 0)
# メガネ対応目検出の実行
eyes_glasses = self.eye_glasses_cascade.detectMultiScale(
roi_gray,
scaleFactor=1.1, # メガネありの場合のスケール設定
minNeighbors=4, # 中間的な条件設定
minSize=(15, 15), # メガネ込みの最小サイズ
maxSize=(80, 80) # メガネ込みの最大サイズ
)
# 座標補正処理
if face_roi is not None and len(eyes_glasses) > 0:
# x座標を元画像座標系に補正
eyes_glasses[:, 0] += detection_area[0]
# y座標を元画像座標系に補正
eyes_glasses[:, 1] += detection_area[1]
# 検出結果を返す
return eyes_glasses
except Exception as e:
print(f"メガネ対応目検出中にエラーが発生しました {e}")
return []メガネ対応の分類器は、通常の目検出では困難なメガネをかけた状態でも目を検出できる特別な学習済みモデルです。
検出結果描画機能の実装
検出された顔と目に矩形を描画するメソッドを追加します。
def draw_detection_results(self, frame, faces, eyes):
"""
検出結果を画像に矩形とラベルで描画するメソッド
顔と目を異なる色で視覚的に区別
Args:
frame: 描画対象のカラー画像
faces: 検出された顔の座標配列
eyes: 検出された目の座標配列
Returns:
numpy.ndarray: 描画処理完了後の画像データ
"""
# 入力画像の存在確認
if frame is None:
return frame
# 元画像を保護するためコピーを作成
result_frame = frame.copy()
# 検出された顔に矩形とラベルを描画
for (x, y, w, h) in faces:
# 緑色の矩形で顔を囲む
cv.rectangle(
result_frame, # 描画対象の画像
(x, y), # 矩形の左上角座標
(x + w, y + h), # 矩形の右下角座標
(0, 255, 0), # 色指定(BGR形式で緑色)
2 # 矩形線の太さ
)
# 顔矩形の上部に「Face」ラベルを表示
cv.putText(
result_frame,
'Face', # 表示する文字列
(x, y - 10), # 文字の表示位置
cv.FONT_HERSHEY_SIMPLEX, # フォントの種類
0.6, # 文字サイズ
(0, 255, 0), # 文字色(緑色)
2 # 文字の太さ
)
# 検出された目に矩形とラベルを描画
for (x, y, w, h) in eyes:
# 青色の矩形で目を囲む
cv.rectangle(
result_frame,
(x, y), # 矩形の左上角座標
(x + w, y + h), # 矩形の右下角座標
(255, 0, 0), # 色指定(BGR形式で青色)
1 # 矩形線の太さ(目は細く)
)
# 目矩形の上部に「Eye」ラベルを表示
cv.putText(
result_frame,
'Eye', # 表示する文字列
(x, y - 5), # 文字の表示位置
cv.FONT_HERSHEY_SIMPLEX, # フォントの種類
0.4, # 小さめの文字サイズ
(255, 0, 0), # 文字色(青色)
1 # 文字の太さ
)
# 描画完了した画像を返す
return result_framecv.rectangle()は矩形を描画する関数で、cv.putText()はテキストを描画する関数です。BGR形式は、Blue-Green-Redの順序で色を指定するOpenCVの標準カラーフォーマットです。
統合検出処理機能の実装
顔と目の検出を統合して実行するメソッドを追加します。
def perform_detection(self, frame, gray_frame):
"""
顔と目の検出を統合実行して結果描画するメソッド
検出ロジックと描画処理を一元管理
Args:
frame: 元のカラー画像
gray_frame: グレースケール変換済み画像
Returns:
numpy.ndarray: 検出結果が描画された画像
"""
# 入力画像の存在確認
if frame is None or gray_frame is None:
return frame
# Step1 顔検出の実行
faces = self.detect_faces(gray_frame)
# Step2 目検出の実行準備
all_eyes = [] # 全ての目検出結果を格納
# 顔が検出された場合の処理
if len(faces) > 0:
# 各検出顔に対して目検出を実行
for face in faces:
# 通常の目検出を試行
eyes = self.detect_eyes(gray_frame, face)
# 通常検出で目が見つからず、メガネ対応分類器が利用可能な場合
if len(eyes) == 0 and self.eye_glasses_cascade is not None:
# メガネ対応目検出を試行
eyes = self.detect_eyes_with_glasses(gray_frame, face)
# 検出された目があれば全体リストに追加
if len(eyes) > 0:
all_eyes.extend(eyes)
else:
# 顔が検出されなかった場合は画像全体で目検出
eyes = self.detect_eyes(gray_frame)
if len(eyes) > 0:
all_eyes.extend(eyes)
# Step3 検出結果の描画
result_frame = self.draw_detection_results(frame, faces, all_eyes)
# 検出状況をコンソールに出力(デバッグ用)
if len(faces) > 0 or len(all_eyes) > 0:
print(f"検出結果 顔{len(faces)}個, 目{len(all_eyes)}個")
# 描画完了した画像を返す
return result_frameこのメソッドは、顔検出→目検出→描画の一連の流れを統合して処理します。顔が見つからない場合の全体検索も含んでいます。
メインループの更新
既存のrun_detectionメソッドを更新して、実際の検出処理を実行するようにします。
def run_detection(self):
"""
リアルタイム検出のメインループ実行メソッド
カメラ初期化から検出処理、結果表示まで全体制御
"""
# Step1 カメラの初期化処理
if not self.setup_camera():
print("カメラ初期化失敗のため終了します")
return
# Step2 カスケード分類器の読み込み処理
if not self.load_cascades():
print("カスケード分類器読み込み失敗のため終了します")
# カメラリソース解放してから終了
self.cleanup()
return
# Step3 システム動作開始の準備
self.is_running = True
print("検出システムを開始します")
print("顔と目の検出を開始します...")
print("終了するには 'q' キーまたはESCキーを押してください")
print("※ウィンドウをクリックしてからキーを押してください")
# カウンタ変数の初期化
frame_count = 0 # 処理したフレーム数
error_count = 0 # 連続エラー数
max_errors = 10 # 許可する最大連続エラー数
detection_count = 0 # 検出成功回数
try:
# Step4 メインループ開始
while self.is_running:
# フレーム取得処理
success, frame = self.capture_frame()
# フレーム取得失敗の場合
if not success:
error_count += 1
print(f"フレーム取得エラー ({error_count}/{max_errors})")
# 連続エラーが上限に達した場合は終了
if error_count >= max_errors:
print("連続エラー上限に達したため終了します")
break
# 次のループに進む
continue
# フレーム取得成功時の処理
error_count = 0 # エラーカウントをリセット
frame_count += 1 # 成功フレーム数をカウント
# Step5 検出前準備処理
processed_frame, gray_frame = self.prepare_detection(frame)
# 準備処理失敗時はスキップ
if processed_frame is None:
continue
# 以下を変更 Step6 検出処理と結果描画を実行
detection_frame = self.perform_detection(processed_frame, gray_frame)
# 検出結果が描画された画像を表示
self.display_frame(detection_frame)
# 初回表示時のみウィンドウフォーカス設定
if frame_count == 1:
self.ensure_window_focus()
# 終了キー入力チェック
if self.check_exit_key():
print("終了キーが検出されました")
self.is_running = False
break
# Ctrl+Cでの強制終了をキャッチ
except KeyboardInterrupt:
print("\nプログラムが中断されました")
# 正常・異常終了に関わらず実行される処理
finally:
print(f"総フレーム数 {frame_count}")
# リソース解放処理を実行
self.cleanup()メインループに実際の検出処理(perform_detection)を組み込み、検出結果が描画されたフレームを表示するように変更しました。
メイン実行部分の更新
main関数の説明を更新します。
def main():
"""
プログラムのメイン実行関数
WebcamDetectorオブジェクトを作成してシステム開始
"""
# システム開始のお知らせ
print("=== リアルタイム顔・目検出システム ===")
print("Webカメラを使用したリアルタイム検出を開始します")
print("顔は緑色の矩形、目は青色の矩形で表示されます")
print()
# WebcamDetectorのインスタンス(実体)を作成
detector = WebcamDetector()
# 検出システムのメイン処理を開始
detector.run_detection()
# システム終了のお知らせ
print("プログラムを終了します")
# スクリプトが直接実行された場合のみmain関数を呼び出し
if __name__ == "__main__":
main()動作テスト実行
VSCodeのターミナルでプログラムを実行してテストします。仮想環境がアクティベートされていることを確認してから実行してください。
Windows環境の場合
python src/webcam_detector.pymacOS環境の場合
python3 src/webcam_detector.py
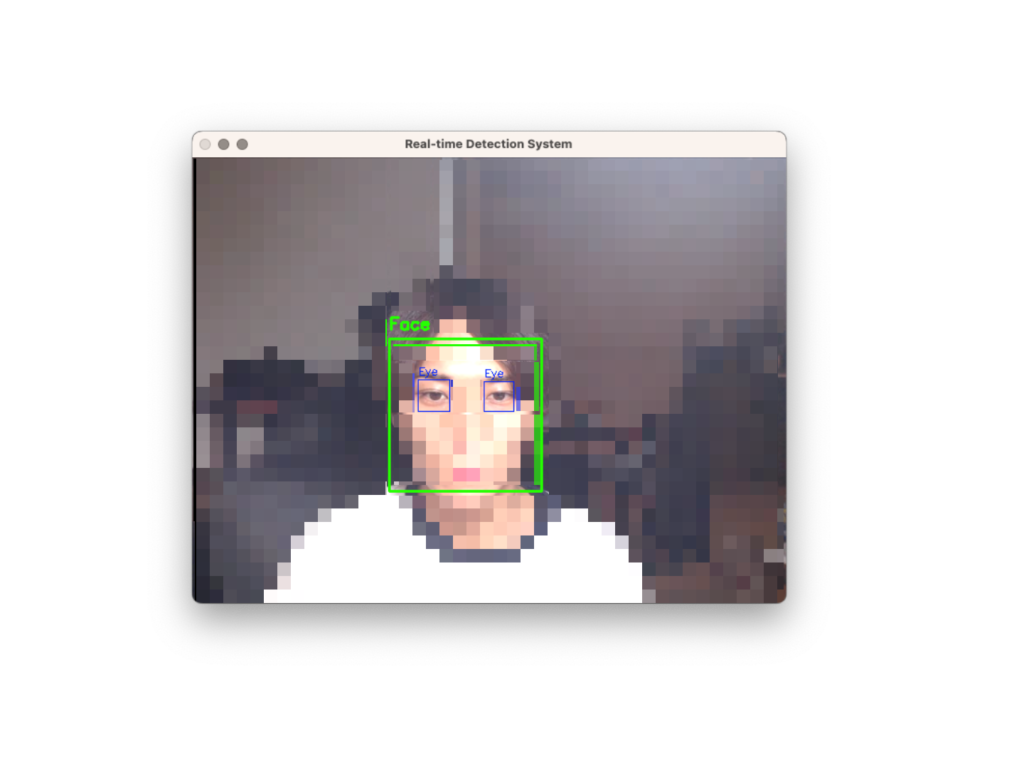
プログラムが正常に動作すると、Webカメラの映像に顔(緑の矩形)と目(青の矩形)が検出されてリアルタイムで表示されます。顔や目が検出されるたびにコンソールに検出個数が表示されます。
GUI画面(実際のGUIにはモザイクはありません)
Step5:プログラムの完成と動作確認
このステップでは、リアルタイム顔・目検出システムの最終的な完成を目指し、検出性能の統計表示、フレームレート計測、エラーハンドリングの強化を実装します。これらの機能により、システムの動作状況を詳細に把握できるようになります。
統計情報管理機能の実装
WebcamDetectorクラスに、検出統計を管理する機能を追加します。「src/webcam_detector.py」ファイルを開き、初期化メソッドに統計関連の属性を追加してください。
def __init__(self):
"""
WebcamDetectorクラスの初期化メソッド
オブジェクト作成時に自動で呼ばれる
"""
# カメラ関連の初期値設定
self.camera = None # Webカメラオブジェクト格納用
self.is_running = False # システム動作状態の管理フラグ
self.window_name = "Real-time Detection System" # 表示ウィンドウ名
self.camera_index = 0 # 使用カメラの番号(0が標準)
# カスケード分類器関連の初期値設定
self.face_cascade = None # 顔検出用分類器オブジェクト
self.eye_cascade = None # 目検出用分類器オブジェクト
self.eye_glasses_cascade = None # メガネ対応目検出用分類器オブジェクト
self.classifiers_loaded = False # 分類器読み込み完了フラグ
# 以下を追加 統計情報管理用の初期値設定
self.total_faces_detected = 0 # 累計検出顔数
self.total_eyes_detected = 0 # 累計検出目数
self.frames_with_faces = 0 # 顔が写ったフレーム数
self.frames_with_eyes = 0 # 目が写ったフレーム数
self.start_time = None # システム開始時刻記録用
self.last_fps_time = None # FPS計算用の前回時刻
self.fps_counter = 0 # FPS計算用のフレームカウンタ
self.current_fps = 0 # 現在のFPS値保存用新しく追加した属性は、検出統計とフレームレート計測のためのものです。
フレームレート計測機能の実装
リアルタイム処理の性能を測定するフレームレート(FPS)計測機能を追加します。
def calculate_fps(self):
"""
現在のフレームレート(FPS)を計算するメソッド
1秒間に処理できたフレーム数を測定
Returns:
float: 現在のFPS値
"""
# 現在時刻を取得
current_time = time.time()
# 初回実行時の初期化処理
if self.last_fps_time is None:
self.last_fps_time = current_time
self.fps_counter = 0
return 0.0
# フレームカウンタを増加
self.fps_counter += 1
# 前回計算から1秒経過したかチェック
time_elapsed = current_time - self.last_fps_time
if time_elapsed >= 1.0:
# FPS値を計算(フレーム数 ÷ 経過時間)
self.current_fps = self.fps_counter / time_elapsed
# 次回計算に向けてリセット
self.fps_counter = 0
self.last_fps_time = current_time
# 現在のFPS値を返す
return self.current_fpsFPS(Frames Per Second)は、1秒間に処理できるフレーム数を示す指標で、リアルタイム映像処理の性能を測る重要な値です。一般的にWebカメラ映像では30FPS程度が目標値になります。
検出統計更新機能の実装
検出結果の統計情報を更新するメソッドを追加します。
def update_detection_stats(self, faces_count, eyes_count):
"""
検出統計情報を更新するメソッド
毎フレームの検出結果を累積して記録
Args:
faces_count (int): 今回フレームで検出された顔の数
eyes_count (int): 今回フレームで検出された目の数
"""
# 累計検出数に加算
self.total_faces_detected += faces_count
self.total_eyes_detected += eyes_count
# 検出があったフレーム数をカウント
if faces_count > 0:
self.frames_with_faces += 1
if eyes_count > 0:
self.frames_with_eyes += 1このメソッドは、各フレームでの検出結果を累積して、全体的な検出統計を管理します。
画面表示情報拡張機能の実装
検出結果に統計情報とFPSを表示する機能を追加します。
def draw_system_info(self, frame, faces_count, eyes_count, frame_count):
"""
画像にシステム情報(FPS、統計データ)を描画するメソッド
リアルタイムでシステム状況を画面表示
Args:
frame: 描画対象の画像
faces_count (int): 現在フレームの顔検出数
eyes_count (int): 現在フレームの目検出数
frame_count (int): 総処理フレーム数
Returns:
numpy.ndarray: システム情報が描画された画像
"""
# 入力画像の存在確認
if frame is None:
return frame
# 画像サイズを取得
height, width = frame.shape[:2]
# 現在のFPS値を計算
fps = self.calculate_fps()
# 情報表示用の半透明背景を作成
overlay = frame.copy()
# 黒い矩形を描画(左上角に配置)
cv.rectangle(overlay, (10, 10), (300, 120), (0, 0, 0), -1)
# 元画像と重み付き合成で半透明効果を作成
frame = cv.addWeighted(overlay, 0.7, frame, 0.3, 0)
# 表示する情報文字列を作成
info_text = [
f"FPS: {fps:.1f}", # フレームレート
f"Frame: {frame_count}", # 総フレーム数
f"Faces: {faces_count} (Total: {self.total_faces_detected})", # 顔検出情報
f"Eyes: {eyes_count} (Total: {self.total_eyes_detected})" # 目検出情報
]
# 各情報を順番に画面に描画
for i, text in enumerate(info_text):
# 表示位置を計算(20ピクセル間隔で縦に配置)
y_position = 30 + i * 20
# 白色文字で情報を描画
cv.putText(
frame,
text, # 表示文字列
(15, y_position), # 表示位置
cv.FONT_HERSHEY_SIMPLEX, # フォント種類
0.5, # 文字サイズ
(255, 255, 255), # 文字色(白色)
1 # 文字の太さ
)
# 情報描画完了した画像を返す
return framecv.addWeighted()は、2つの画像を重み付きで合成する関数で、半透明の背景効果を作成できます。これにより情報表示エリアが見やすくなります。
検出パラメータ最適化機能の実装
検出精度を向上させるため、既存の検出メソッドのパラメータを微調整します。
def detect_faces(self, gray_frame):
"""
グレースケール画像から顔を検出するメソッド
パラメータ最適化で精度と性能のバランス改善
Args:
gray_frame: グレースケール変換済みの画像データ
Returns:
numpy.ndarray: 検出された顔の座標情報配列 (x, y, width, height)
"""
# 入力画像と分類器の存在確認
if gray_frame is None or self.face_cascade is None:
return []
try:
# detectMultiScale関数で顔検出を実行
faces = self.face_cascade.detectMultiScale(
gray_frame,
scaleFactor=1.05, # より細かいスケール調整(1.1→1.05に変更)
minNeighbors=6, # 誤検出防止を強化(5→6に変更)
minSize=(40, 40), # 最小サイズを拡大(30→40に変更)
maxSize=(250, 250), # 最大サイズを調整(300→250に変更)
flags=cv.CASCADE_SCALE_IMAGE # 検出フラグを追加(性能最適化)
)
# 検出結果を配列で返す
return faces
except Exception as e:
print(f"顔検出中にエラーが発生しました {e}")
return []flags=cv.CASCADE_SCALE_IMAGEは、検出アルゴリズムの動作を制御するフラグで、画像スケーリングの最適化を行います。
安全な検出処理実行機能の実装
システムの安定性を向上させるためのエラーハンドリングを強化します。
def safe_detection_execute(self, frame, gray_frame):
"""
安全な検出処理実行メソッド
例外処理を強化してシステム安定性を向上
Args:
frame: 元のカラー画像
gray_frame: グレースケール変換済み画像
Returns:
tuple: (処理済み画像, 顔検出数, 目検出数) の組み合わせ
"""
try:
# Step1 顔検出の実行
faces = self.detect_faces(gray_frame)
# Step2 目検出の実行準備
all_eyes = [] # 全ての目検出結果を格納
# 顔が検出された場合の処理
if len(faces) > 0:
# 各検出顔に対して目検出を実行
for face in faces:
# 通常の目検出を試行
eyes = self.detect_eyes(gray_frame, face)
# 通常検出で目が見つからず、メガネ対応分類器が利用可能な場合
if len(eyes) == 0 and self.eye_glasses_cascade is not None:
# メガネ対応目検出を試行
eyes = self.detect_eyes_with_glasses(gray_frame, face)
# 検出された目があれば全体リストに追加
if len(eyes) > 0:
all_eyes.extend(eyes)
else:
# 顔が検出されなかった場合は画像全体で目検出
eyes = self.detect_eyes(gray_frame)
if len(eyes) > 0:
all_eyes.extend(eyes)
# Step3 検出結果の描画
result_frame = self.draw_detection_results(frame, faces, all_eyes)
# 処理結果を返す(画像、顔数、目数)
return result_frame, len(faces), len(all_eyes)
# OpenCV固有のエラーをキャッチ
except cv.error as e:
print(f"OpenCV処理エラー {e}")
return frame, 0, 0
# その他の予期しないエラーをキャッチ
except Exception as e:
print(f"予期しないエラーが発生しました {e}")
return frame, 0, 0このメソッドは、cv.error(OpenCV固有のエラー)と一般的な例外を分けて処理し、エラーが発生してもシステムが停止しないようにします。
メインループの最終更新
既存のrun_detectionメソッドを最終的に更新して、すべての新機能を統合します。
def run_detection(self):
"""
リアルタイム検出のメインループ実行メソッド
全機能を統合した完全版の処理制御
"""
# Step1 カメラの初期化処理
if not self.setup_camera():
print("カメラ初期化失敗のため終了します")
return
# Step2 カスケード分類器の読み込み処理
if not self.load_cascades():
print("カスケード分類器読み込み失敗のため終了します")
# カメラリソース解放してから終了
self.cleanup()
return
# 以下を追加 Step3 開始時刻を記録(統計計算用)
self.start_time = time.time()
# Step4 システム動作開始の準備
self.is_running = True
print("検出システムを開始します")
print("顔(緑)と目(青)の検出を開始します...")
print("画面左上にFPSと統計情報が表示されます")
print("終了するには 'q' キーまたはESCキーを押してください")
print("※ウィンドウをクリックしてからキーを押してください")
# カウンタ変数の初期化
frame_count = 0 # 処理したフレーム数
error_count = 0 # 連続エラー数
max_errors = 10 # 許可する最大連続エラー数
try:
# Step5 メインループ開始
while self.is_running:
# フレーム取得処理
success, frame = self.capture_frame()
# フレーム取得失敗の場合
if not success:
error_count += 1
print(f"フレーム取得エラー ({error_count}/{max_errors})")
# 連続エラーが上限に達した場合は終了
if error_count >= max_errors:
print("連続エラー上限に達したため終了します")
break
# 次のループに進む
continue
# フレーム取得成功時の処理
error_count = 0 # エラーカウントをリセット
frame_count += 1 # 成功フレーム数をカウント
# Step6 検出前準備処理
processed_frame, gray_frame = self.prepare_detection(frame)
# 準備処理失敗時はスキップ
if processed_frame is None:
continue
# 以下を変更 Step7 安全な検出処理を実行
detection_frame, faces_count, eyes_count = self.safe_detection_execute(processed_frame, gray_frame)
# Step8 統計情報を更新
self.update_detection_stats(faces_count, eyes_count)
# Step9 システム情報を画面に描画
final_frame = self.draw_system_info(detection_frame, faces_count, eyes_count, frame_count)
# Step10 最終画像を表示
self.display_frame(final_frame)
# 初回表示時のみウィンドウフォーカス設定
if frame_count == 1:
self.ensure_window_focus()
# 終了キー入力チェック
if self.check_exit_key():
print("終了キーが検出されました")
self.is_running = False
break
# Ctrl+Cでの強制終了をキャッチ
except KeyboardInterrupt:
print("\nプログラムが中断されました")
# 正常・異常終了に関わらず実行される処理
finally:
# 以下を追加 最終統計情報を表示
self.print_final_statistics(frame_count)
# リソース解放処理を実行
self.cleanup()統計情報の更新とシステム情報の描画を追加し、最終統計表示機能も含めました。
最終統計表示機能の実装
プログラム終了時に全体の統計情報を表示するメソッドを追加します。
def print_final_statistics(self, total_frames):
"""
プログラム終了時に最終統計情報を表示するメソッド
システム全体の実行結果をまとめて出力
Args:
total_frames (int): 処理した総フレーム数
"""
print("\n=== 検出システム統計情報 ===")
# 実行時間と平均FPSの計算・表示
if self.start_time is not None:
total_time = time.time() - self.start_time
print(f"総実行時間 {total_time:.1f}秒")
if total_time > 0:
avg_fps = total_frames / total_time
print(f"平均FPS {avg_fps:.1f}")
# 基本統計情報の表示
print(f"総処理フレーム数 {total_frames}")
print(f"総検出顔数 {self.total_faces_detected}")
print(f"総検出目数 {self.total_eyes_detected}")
# 検出率の計算・表示
if total_frames > 0:
face_detection_rate = (self.frames_with_faces / total_frames) * 100
eye_detection_rate = (self.frames_with_eyes / total_frames) * 100
print(f"顔検出率 {face_detection_rate:.1f}%")
print(f"目検出率 {eye_detection_rate:.1f}%")
print("=========================")このメソッドは、実行時間、平均FPS、検出率などの有用な統計情報を表示します。
メイン実行部分の最終更新
main関数の説明を最終版に更新します。
def main():
"""
プログラムのメイン実行関数
WebcamDetectorオブジェクトを作成してシステム開始
"""
# システム開始のお知らせ
print("=== リアルタイム顔・目検出システム ===")
print("OpenCVカスケード分類器による高精度検出")
print("顔は緑色の矩形、目は青色の矩形で表示されます")
print("画面左上にリアルタイム統計情報が表示されます")
print()
# WebcamDetectorのインスタンス(実体)を作成
detector = WebcamDetector()
# 検出システムのメイン処理を開始
detector.run_detection()
# システム終了のお知らせ
print("プログラムを終了します")
# スクリプトが直接実行された場合のみmain関数を呼び出し
if __name__ == "__main__":
main()動作テスト実行
VSCodeのターミナルでプログラムを実行してテストします。仮想環境がアクティベートされていることを確認してから実行してください。
Windows環境の場合
python src/webcam_detector.py
macOS環境の場合
python3 src/webcam_detector.pyプログラムが正常に動作すると、Webカメラの映像に顔(緑の矩形)と目(青の矩形)が検出され、画面左上にFPSと統計情報がリアルタイムで表示されます。プログラム終了時には、詳細な統計情報が表示されます。
GUI画面(実際のGUIにはモザイクはありません)
Step6:プロジェクトをGitHubにアップロード
このステップでは、完成したリアルタイム顔・目検出プロジェクトをGitHubにアップロードし、ポートフォリオとして活用できる形にします。最終的なファイル整理とコードの公開を行っていきます。
.gitignoreファイルの更新
既存の.gitignoreファイルに、プロジェクト固有の除外設定を追加します。
VSCodeで「.gitignore」ファイルを開き、以下の内容を末尾に追加してください。
# Virtual environment
myenv/
# OpenCV temporary files
*.tmp
# System files
.DS_Store
Thumbs.db
# IDE files
.vscode/settings.json
.idea/
# Cache files
__pycache__/
*.pyc
*.pyo
*.pydこれらを追加する理由について説明します。
- myenv/ 仮想環境フォルダはプロジェクト固有のため、リポジトリに含める必要がありません
- *.tmp OpenCVが一時的に作成するファイルを除外
- .DS_Store, Thumbs.db macOSやWindowsが自動生成するシステムファイルを除外
- .vscode/settings.json, .idea/ 開発環境固有の設定ファイルを除外
- *pycache/, .pyc Pythonの実行時に生成されるキャッシュファイルを除外
README.mdファイルの更新
リポジトリ作成時に生成されたREADME.mdファイルの内容を、プロジェクトの詳細情報に更新します。
VSCodeで「README.md」ファイルを開き、内容を以下のように全て置き換えてください。
# リアルタイム顔・目検出システム
## プロジェクト概要
Webカメラを使用してリアルタイムで顔と目を検出するコンピュータビジョンシステムです。OpenCVライブラリのカスケード分類器を活用し、機械学習による物体検出技術を実装しています。検出された顔は緑色、目は青色の矩形で表示され、FPSや検出統計情報もリアルタイムで確認できます。
## プロジェクト構成
```
realtime-face-detection/
├── src/
│ └── webcam_detector.py # メインプログラム
├── classifiers/
│ ├── haarcascade_frontalface_default.xml # 顔検出用分類器
│ ├── haarcascade_eye.xml # 目検出用分類器
│ └── haarcascade_eye_tree_eyeglasses.xml # メガネ対応目検出用分類器
├── requirements.txt # 依存関係管理
├── README.md # プロジェクト説明書
└── .gitignore # Git除外ファイル設定
```
## 必要要件・開発環境
- **Python 3.7以上**
- **VSCode** (開発環境)
- **Git** (バージョン管理)
- **Webカメラ** (内蔵またはUSB接続)
### 使用ライブラリ
- **opencv-python** コンピュータビジョンと画像処理
- **numpy** 数値計算(OpenCVの依存関係)
- **time** FPS計測とタイミング制御
- **os** ファイルシステム操作
## 技術仕様
### 検出アルゴリズム
- **カスケード分類器** Haar特徴量ベースの機械学習検出器
- **マルチスケール検出** 異なるサイズの顔・目を検出
- **ROI処理** 関心領域に限定した効率的な検出
### パフォーマンス
- **リアルタイム処理** 30FPS対応
- **複数カメラ対応** 自動カメラ検索機能
- **エラーハンドリング** 堅牢な例外処理システム
## 機能一覧
- **リアルタイム顔検出** Webカメラ映像から顔を自動検出
- **リアルタイム目検出** 検出された顔領域内で目を検出
- **メガネ対応検出** メガネ着用時でも目を検出可能
- **FPS表示** リアルタイムフレームレート表示
- **統計情報表示** 検出数、検出率の統計データ表示
- **視覚的フィードバック** 検出結果の矩形とラベル表示
- **キーボード制御** 'q'キーまたはESCキーでの終了
- **自動カメラ検索** 利用可能なカメラの自動検出
- **安全なリソース管理** カメラとウィンドウの適切な解放
## 実行方法
### 1. リポジトリのクローン
```bash
git clone https://github.com/yourusername/realtime-face-detection.git
cd realtime-face-detection
```
### 2. 仮想環境の作成・アクティベート
**Windows環境**
```bash
python -m venv myenv
myenv\Scripts\activate
```
**macOS環境**
```bash
python3 -m venv myenv
source myenv/bin/activate
```
### 3. 依存関係のインストール
```bash
pip install -r requirements.txt
```
### 4. プログラムの実行
**Windows環境**
```bash
python src/webcam_detector.py
```
**macOS環境**
```bash
python3 src/webcam_detector.py
```
### 5. 操作方法
- プログラム起動後、Webカメラ映像が表示されます
- 顔が緑色の矩形、目が青色の矩形で囲まれます
- 画面左上にFPSと統計情報が表示されます
- 'q'キーまたはESCキーで終了します
## トラブルシューティング
### カメラアクセスエラーの場合
- **macOS** システム環境設定 → セキュリティとプライバシー → カメラ
- **Windows** 設定 → プライバシー → カメラ
- ターミナルまたはVSCodeにカメラアクセス許可を与えてください
### パフォーマンスが低い場合
- 他のカメラ使用アプリケーションを終了してください
- 照明条件を改善してください
- カメラの解像度設定を確認してください
## 学習した技術
- **OpenCVライブラリの活用方法**
- **カスケード分類器による物体検出**
- **リアルタイム映像処理技術**
- **Pythonクラス設計とオブジェクト指向プログラミング**
- **エラーハンドリングとリソース管理**
- **FPS計測とパフォーマンス最適化**
## 開発者
YuYu(あなたの名前に置き換えてください)
プロジェクトのコミット・プッシュ
プロジェクトの全ての変更をGitHubに反映させましょう。
変更のステージングとコミット
- VSCodeの左側のアクティビティバーからソース管理アイコンをクリックします
- 変更内容セクションで、すべての変更ファイルを確認します
- 各ファイルの横にある「+」アイコンをクリックしてステージングします
- コミットメッセージ入力欄に「Add real-time face and eye detection system」と入力します
- 「コミット」ボタンをクリックします
GitHubへのプッシュ
- コミット完了後、「変更の同期」または「プッシュ」ボタンをクリックします
- 初回の場合、GitHub認証が求められる場合があります
- 認証完了後、ローカルの変更がGitHubリポジトリに反映されます
GitHubでの確認
プロジェクトが正常にアップロードされたか確認しましょう。
- ブラウザでGitHubリポジトリページを開きます
- 以下のファイルが正しくアップロードされていることを確認します
- src/webcam_detector.py (メインプログラムファイル)
- classifiers/haarcascade_frontalface_default.xml (顔検出用分類器)
- classifiers/haarcascade_eye.xml (目検出用分類器)
- classifiers/haarcascade_eye_tree_eyeglasses.xml (メガネ対応目検出用分類器)
- requirements.txt (依存関係管理ファイル)
- README.md (更新されたプロジェクト説明書)
- .gitignore (更新された除外設定ファイル)
- README.mdが適切に表示され、プロジェクトの説明が読みやすく表示されていることを確認します
- ファイル一覧にmyenv/フォルダやpycache/フォルダが含まれていないことを確認します(.gitignoreで除外されているため)
これで本格的なリアルタイム顔・目検出システムが完成し、GitHubでのポートフォリオ公開も完了しました。作成したプロジェクトは、コンピュータビジョン技術とリアルタイム映像処理のスキルを示す実用的なシステムとして、就職活動や案件獲得時の実績として活用できます。
まとめ
このプロジェクトを通じて、OpenCVとカスケード分類器を使用したリアルタイム物体検出の基礎から実践的な応用まで幅広く学習することができました。
得られたスキル
- OpenCVライブラリ – コンピュータビジョンと画像処理の基本操作
- カスケード分類器 – 機械学習ベースの物体検出技術
- リアルタイム映像処理 – Webカメラからの連続フレーム処理と最適化
- FPS計測とパフォーマンス最適化 – システム性能の測定と改善手法
- Pythonクラス設計 – オブジェクト指向プログラミングと保守性の高いコード構造
- エラーハンドリング – 例外処理と安定したシステム運用
得られた経験
- Webカメラからのリアルタイム映像取得と処理の実践経験
- 機械学習モデル(分類器)の実装と活用経験
- コンピュータビジョン分野での実践的な開発経験
- GitHubを使用したバージョン管理の実践的経験
得られた成果物
- 完全に動作するリアルタイム顔・目検出システム
- GitHubでのポートフォリオとして活用可能なプロジェクト
- 完全なPythonソースコード
次に学ぶべきこと
- 他の物体検出(手、表情など)の実装による機能拡張
- 検出結果のファイル保存機能の追加
- 複数人同時検出の精度向上
- 簡単なログ機能の実装による使用状況の記録
このプロジェクトから応用できること
- 入退室管理システムの基盤開発(OpenCVとカスケード分類器を使用して顔認識機能を実装)
- Web会議での自動フォーカス機能の実装(リアルタイム顔検出技術を活用してカメラ制御)
- 防犯カメラシステムの人物検出機能(カスケード分類器による検出技術を応用)
- アプリの顔認証機能の基礎実装(OpenCVの検出技術を基盤とした認証システム)
- 写真の自動分類システムの開発(物体検出技術を活用した画像整理)
- 顔検出機能を活用したWebアプリの受託開発
このコンピュータビジョン技術を基盤として、様々な業界での自動化ニーズや画像認識が必要な業務に対応できるサービスを開発することが可能です。特に、リアルタイム処理が必要な業務では、高い価値を提供できる技術として活用できます。

本コンテンツへの意見や質問