

DEMO
このプロジェクトの完成イメージを以下の動画でご確認いただけます。テキストプロンプトを入力して画像を生成し、保存、バリエーション作成までの一連の流れを実際に体験できます。
動画ではStreamlitインターフェースを通じて、「富士山と桜」というプロンプトから画像を生成し、その画像からバリエーションを作成する過程を紹介しています。シンプルなテキスト入力から始まり、DALL-Eの強力な画像生成能力によって、わずか数秒でプロンプトが視覚化されていく様子が確認できます。
また、Base64エンコードされた画像データをローカルに保存し、いつでも参照できる機能や、ワンクリックでバリエーションを作成できる便利な機能も実演しています。このアプリを使えば、プログラミングとAIの力でクリエイティブなアイデアを簡単に形にすることができます。
前提条件
このプロジェクトを実行するには、以下の準備が必要です。
必要なもの
- Python 3.7.1以上のインストール
- 最新バージョンをPython公式サイトからダウンロードしてください。
- Pythonの環境構築がわからない方は書き記事を参考にしてください

- OpenAIアカウントとAPIキー
- OpenAIのウェブサイトでアカウントを作成
- ダッシュボードから「APIキー」を選択し、新しいシークレットキーを作成
- 注意: APIキーは絶対に公開しないでください。発行時に一度だけ表示され、再表示はできません。
- OpenAIアカウントとAPIキーの取得方法が不明な方は下記記事を参考にしてください
- 基本的なPythonの知識
- 変数、関数、ライブラリの概念を理解していること
- 仮想環境の作成方法を知っていること
- コマンドラインの基本操作
- ターミナル(MacOS/Linux)またはコマンドプロンプト/PowerShell(Windows)の基本操作
- 十分なディスク容量
- 生成した画像を保存するための空き容量(最低500MB程度)
費用について
- OpenAIのAPIは従量課金制です
- DALL-E 2では1枚あたり約$0.02~$0.04(サイズにより異なる)
- 初回登録時に無料クレジットが付与されることがあります
- 予算管理のため、OpenAIダッシュボードで使用量を定期的に確認しましょう
このプロジェクトはポートフォリオ構築にも最適で、エンジニア採用担当者にPythonスキルと最新技術への理解をアピールできます。完成したアプリはオンラインで共有することも可能です。
プロジェクト概要
このプロジェクトでは、OpenAIのDALL-E APIを使用してテキストから画像を生成するStreamlitアプリケーションを開発します。AIの画像生成能力を活用して、テキストプロンプトを視覚的なアートに変換し、画像のバリエーション作成や保存機能も実装します。
学習目標
- OpenAI Python ライブラリのセットアップと使用
- テキストプロンプトからの画像生成の実装
- Base64エンコードデータからPNG画像への変換
- 既存画像からバリエーションを作成する方法
- Streamlitを使ったインタラクティブWebアプリの開発
プロジェクト構成
ai_art_studio/ # プロジェクトルートディレクトリ
│
├── .venv/ # Python仮想環境(自動生成)
│
├── app.py # メインアプリケーションコード
│
├── generated_images/ # 生成された画像の保存ディレクトリ
│ ├── 富士山_20240404_123456.png # 生成画像例
│ ├── 猫カフェ_20240404_124512.png # 生成画像例
│ └── ... # その他の生成画像
│
└── requirements.txt # 必要なPythonパッケージのリスト
技術スタック
このプロジェクトでは以下の技術を使用します:
- Python – バックエンド処理とAPI連携
- OpenAI API – DALL-Eモデルによる画像生成
- Streamlit – インタラクティブなWebインターフェース
- Pillow – 画像処理
- Pathlib – ファイルパス操作
- Base64 – 画像データのエンコード/デコード
実用的な応用例
このアプリケーションは以下のような用途に活用できます:
- クリエイティブプロジェクトのコンセプト作成:アイデアの視覚化
- ウェブサイトやブログ用のカスタム画像生成:オリジナルコンテンツの作成
- プレゼンテーション資料の画像作成:スライド用のビジュアル素材
- SNS投稿用のユニークな画像作成:エンゲージメント向上
- 商品/サービスのモックアップ画像:プロトタイプのビジュアライゼーション
このプロジェクトで作成するアプリケーションは、単なる実験的なものではなく、実務でも活用できる実用的なツールとなります。また、完成したアプリはポートフォリオとして公開でき、あなたのPythonスキルと最新技術への理解をアピールする強力な材料になります。
Step 1: AIアートスタジオの環境構築
みなさん、こんにちは!今回はOpenAIのDALL-Eという画像生成AIを使って、自分の言葉から画像を作り出すStreamlitアプリを作っていきます。このアプリがあれば、「こんな画像が欲しいな」というイメージを簡単に形にできますよ!
プロジェクトフォルダの作成
まずは、このプロジェクト専用のフォルダを作りましょう。フォルダ名は「ai_art_studio」としてみます。
コードエディター(VSCodeなど)のターミナルで以下のコマンドを実行してください:
Windowsの場合:
mkdir ai_art_studio
cd ai_art_studioMacOS/Linuxの場合:
mkdir ai_art_studio
cd ai_art_studioもちろん、コードエディターのファイル機能を使って手動でフォルダを作成することもできます。
Pythonの仮想環境を準備する
プロジェクトごとに独立した環境を作ることで、パッケージの競合を避けることができます。以下のコマンドで仮想環境を作成・有効化しましょう。
Windowsの場合:
python -m venv .venv
.\.venv\Scripts\activateMacOS/Linuxの場合:
python3 -m venv .venv
source .venv/bin/activateコマンドを実行すると、ターミナルの行頭に(.venv)と表示されるはずです。これで仮想環境の中にいることが確認できます。以降、ターミナルに入力するコマンドは、この(.venv)が表示されている状態で実行してください。
必要なライブラリのインストール
今回のプロジェクトで必要なライブラリをインストールしましょう:
pip3 install streamlit openai pillowこれで以下のライブラリがインストールされました:
- streamlit: 簡単にWebアプリを作るためのライブラリ
- openai: OpenAIのAPIを使うためのライブラリ
- pillow: 画像処理のためのライブラリ
APIキーを環境変数として設定
OpenAIのAPIキーを取得したら、それを環境変数として設定します。環境変数として設定することで、コード内で直接APIキーを書かなくても安全に利用できます。OpenAIのAPIキーの取得方法は下記記事を参考にしてください。
Windowsの場合(コードエディターのターミナル):
$env:OPENAI_API_KEY = "あなたのAPIキー"MacOS/Linuxの場合(コードエディターのターミナル):
export OPENAI_API_KEY="あなたのAPIキー"「あなたのAPIキー」の部分には、取得したAPIキーを入れてください。この方法で設定した環境変数は、ターミナルを閉じると消えてしまうので、プロジェクトを再開するたびに設定が必要です。
コマンドラインからのAI画像生成テスト
環境構築が完了したら、まずはコマンドラインから直接画像生成ができるか確認してみましょう。
Windows/MacOS/Linux共通:
python3 -c "from openai import OpenAI; client = OpenAI(); response = client.images.generate(prompt='四季折々の富士山', n=1, size='256x256'); print(response.data[0].url)"このコマンドを実行すると、「四季折々の富士山」というプロンプトに基づいた画像のURLが表示されます。このURLをブラウザで開くと、AIが生成した画像(毎回異なる)が表示されます。

注意: このURLは1時間だけ有効です。長期間保存したい場合は画像をダウンロードしておきましょう。
Streamlitアプリの基本ファイル作成
最後に、これから開発していくStreamlitアプリの基本ファイルを作成しましょう:
touch app.py作成したapp.pyに以下の内容を書き込みます:
import streamlit as st
from openai import OpenAI
# アプリのタイトルとサブタイトル
st.title("AIアートスタジオ🎨")
st.write("あなたの言葉から絵を描くAIアプリです。お気軽に試してみてください!")
# OpenAIクライアントの初期化
client = OpenAI()
# APIキー接続テスト
try:
# 簡単なリクエストを送信してテスト
models = client.models.list()
st.success("✅ OpenAIとの接続に成功しました!")
except Exception as e:
st.error("❌ OpenAIとの接続に失敗しました。APIキーを確認してください。")
st.error(f"エラー詳細: {e}")
このコードを保存し、以下のコマンドでStreamlitアプリを起動します:
python3 -m streamlit run app.pyコマンドを実行すると、自動的にブラウザが開き、「AIアートスタジオ🎨」というタイトルのページが表示されます。APIキーが正しく設定されていれば「✅ OpenAIとの接続に成功しました!」というメッセージが表示されます。

これで、AIアートスタジオの基本準備が整いました!次のステップでは、実際にテキストから画像を生成する機能を実装していきます。
Step 2: テキストプロンプトから画像を生成する
前のステップでは環境構築を行いました。これからは実際にAIで画像を作る部分に入っていきます!コマンドラインから画像生成ができるのはわかりましたが、それをStreamlitアプリに組み込んでより使いやすくしていきましょう。
基本的な画像生成の仕組み
まず、Streamlitでプロンプト(お題)を入力するフォームを作り、そのテキストをもとにAIが画像を生成する仕組みを作ります。
app.pyファイルを開いて、以下のように編集しましょう
import streamlit as st
from openai import OpenAI
import time
# アプリのタイトルとガイド
st.title("AIアートスタジオ🎨")
st.write("あなたの言葉から絵を描くAIアプリです。下のフォームに描いて欲しいものを入力してください!")
# OpenAIクライアントの初期化
client = OpenAI()
# モデル選択
model = st.radio("モデル", ["DALL-E 2", "DALL-E 3"], index=0)
model_name = "dall-e-2" if model == "DALL-E 2" else "dall-e-3"
# モデルによって利用可能なサイズが異なる
if model == "DALL-E 2":
size_options = ["256x256", "512x512", "1024x1024"]
default_size = "512x512"
else: # DALL-E 3
size_options = ["1024x1024", "1024x1792", "1792x1024"]
default_size = "1024x1024"
# 画像サイズ選択
size = st.selectbox("画像サイズ", options=size_options, index=size_options.index(default_size))
# 画像生成用の入力フォーム
prompt = st.text_input("描いて欲しいものを入力してください",
value="和風の庭園と金閣寺",
key="prompt_input")
# 生成ボタンが押されたら画像を生成
if st.button("画像を生成する✨", key="generate_button"):
with st.spinner("AIが画像を生成中...少々お待ちください"):
# OpenAIのAPIを呼び出して画像を生成
response = client.images.generate(
model=model_name, # 選択したモデルを使用
prompt=prompt,
n=1, # 1枚の画像を生成
size=size, # 選択したサイズで生成
)
# 生成された画像のURLを取得
image_url = response.data[0].url
# 画像を表示
st.image(image_url, caption=f"プロンプト: {prompt}")
# DALL-E 3の場合は改良されたプロンプトを表示
if model == "DALL-E 3" and hasattr(response.data[0], 'revised_prompt'):
with st.expander("AIが改良したプロンプト"):
st.write(response.data[0].revised_prompt)
# URLも表示(ダウンロードしたい場合に便利)
st.write("画像URL(1時間のみ有効):")
st.write(image_url)このコードを保存して、以下のコマンドでアプリを起動しましょう:
python3 -m streamlit run app.pyブラウザが開いて、テキスト入力フォームと「画像を生成する✨」ボタンが表示されるはずです。
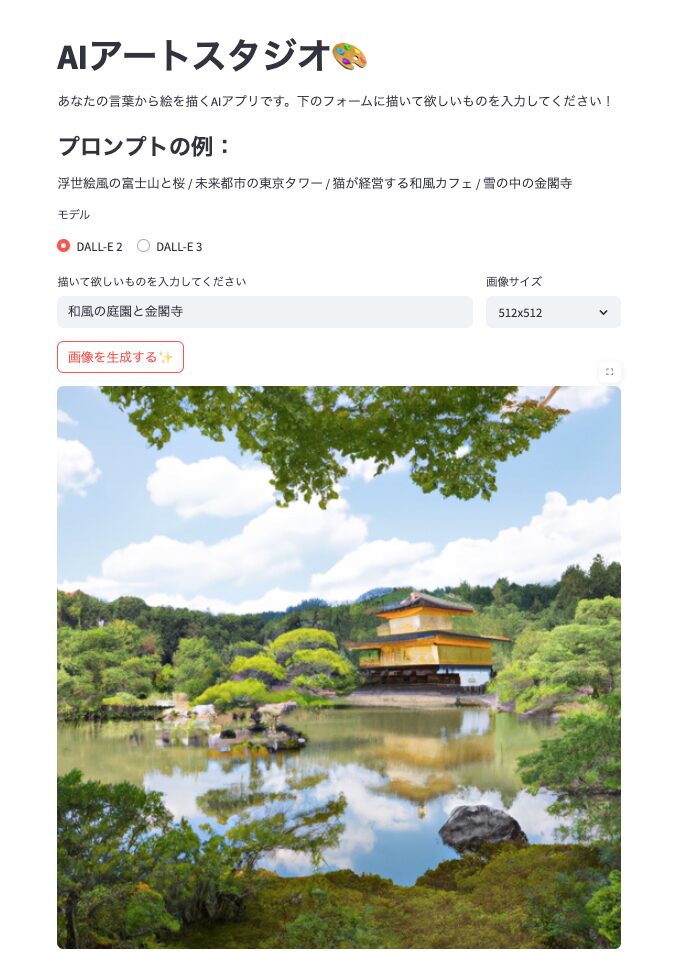
コードの解説
このコードでは以下のことを行っています:
- 必要なライブラリのインポート:Streamlit、OpenAI、time(処理時間表示用)をインポートしています。
- モデル選択機能:
- DALL-E 2とDALL-E 3から選択できるラジオボタン
- モデルによって利用可能な画像サイズが異なるため、動的に選択肢を変更
- ユーザー入力の受け取り:
st.text_input()でユーザーからプロンプト(お題)を受け取ります。初期値として「和風の庭園と金閣寺」を設定していますが、好きな文字を入力できます。 - 画像生成処理:「画像を生成する✨」ボタンがクリックされたら、OpenAIのAPIを呼び出して画像を生成します。
- パラメーターの設定:
- model: 選択したモデル(”dall-e-2″または”dall-e-3″)を指定
- prompt: ユーザーが入力したテキスト(お題)
- n: 生成する画像の枚数(ここでは1枚)
- size: 選択した画像サイズ
- 結果の表示:生成された画像のURLを取得し、Streamlitの
st.image()関数で画像を表示します。 - DALL-E 3のプロンプト改良表示:DALL-E 3を使用した場合、AIが自動的に改良したプロンプトを表示します。
DALL-E 2とDALL-E 3の違い
OpenAIには「DALL-E 2」と「DALL-E 3」という2つの画像生成モデルがあります。違いを理解しておきましょう:
- DALL-E 3:
- 最新のモデルで、より高品質で詳細な画像を生成します
- ユーザーのプロンプトを自動的に改良して詳細にします
- 例えば「可愛い猫」というプロンプトを「ふわふわの毛並みを持つ、大きな青い目の愛らしい子猫が、日当たりの良い窓辺で丸くなっている」のように詳細化します
- 利用可能なサイズ: 「1024×1024」「1024×1792」「1792×1024」
- 生成コストが高いですが、品質も高い
- DALL-E 2:
- 少し古いモデルですが、コスト効率が良いです
- プロンプトの自動改良機能はありません
- 入力したプロンプトをそのまま使用します
- 利用可能なサイズ: 「256×256」「512×512」「1024×1024」
- サイズが小さいほど生成コストが安い
プロンプトのコツ
AIに良い画像を生成してもらうためのプロンプト(お題)のコツをいくつか紹介します:
- 具体的に描写する:「猫」よりも「夕日を眺める三毛猫」の方が良い結果になります
- アーティスト名や画風を指定する:「ジブリ風の」「浮世絵スタイルの」など
- 色や構図を指定する:「青と紫を基調とした」「俯瞰視点の」など
- 日本語と英語の組み合わせ:「富士山 in watercolor style」のように、日本語と英語を組み合わせるのも効果的です
- 詳細な説明を加える:「光の反射がある」「霧がかかった」など、細かい表現を追加するとより具体的になります
実践:ユーザーインターフェースの改良
さらに使いやすくするため、プロンプトの例を追加し、少しアプリを改良してみましょう。以下のようにコードを変更します
import streamlit as st
from openai import OpenAI
import time
# アプリのタイトルとガイド
st.title("AIアートスタジオ🎨")
st.write("あなたの言葉から絵を描くAIアプリです。下のフォームに描いて欲しいものを入力してください!")
# プロンプトの例を表示
st.subheader("プロンプトの例:")
examples = [
"浮世絵風の富士山と桜",
"未来都市の東京タワー",
"猫が経営する和風カフェ",
"雪の中の金閣寺"
]
example_text = " / ".join(examples)
st.write(example_text)
# OpenAIクライアントの初期化
client = OpenAI()
# モデル選択
model = st.radio("モデル", ["DALL-E 2", "DALL-E 3"], index=0, horizontal=True, key="model_radio")
model_name = "dall-e-2" if model == "DALL-E 2" else "dall-e-3"
# モデルによって利用可能なサイズが異なる
if model == "DALL-E 2":
size_options = ["256x256", "512x512", "1024x1024"]
default_size = "512x512"
else: # DALL-E 3
size_options = ["1024x1024", "1024x1792", "1792x1024"]
default_size = "1024x1024"
# 画像生成設定
col1, col2 = st.columns([3, 1])
with col1:
prompt = st.text_input("描いて欲しいものを入力してください",
value="和風の庭園と金閣寺",
key="prompt_input")
with col2:
size = st.selectbox("画像サイズ",
options=size_options,
index=size_options.index(default_size),
key="size_select")
# 生成ボタンが押されたら画像を生成
if st.button("画像を生成する✨", key="generate_button"):
if not prompt:
st.error("プロンプトを入力してください")
else:
with st.spinner("AIが画像を生成中...少々お待ちください"):
try:
# OpenAIのAPIを呼び出して画像を生成
response = client.images.generate(
model=model_name,
prompt=prompt,
n=1,
size=size,
)
# 生成された画像のURLを取得
image_url = response.data[0].url
# 画像を表示
st.image(image_url, caption=f"プロンプト: {prompt}", use_container_width=True)
# DALL-E 3の場合は改良されたプロンプトを表示
if model == "DALL-E 3" and hasattr(response.data[0], 'revised_prompt'):
with st.expander("AIが改良したプロンプト"):
st.write(response.data[0].revised_prompt)
# URLも表示(ダウンロードしたい場合に便利)
with st.expander("画像URL(1時間のみ有効)"):
st.write(image_url)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
st.warning("APIキーの設定や入力内容を確認してください。不適切な内容の画像は生成できません。")このように改良することで、ユーザーは:
- プロンプトの例を参考にできる
- モデルとサイズを選択できる
- 改良されたプロンプトを確認できる(DALL-E 3の場合)
- エラーが発生した場合に詳細なメッセージを見ることができる
ぜひアプリを起動して、さまざまなプロンプトや設定で画像生成を試してみてください!次のステップでは、生成した画像をファイルとして保存する方法を学びます。
ぜひアプリを起動して、さまざまなプロンプトや設定で画像生成を試してみてください!次のステップでは、生成した画像をファイルとして保存する方法を学びます。
Step 3: 生成画像をローカルに保存する
前のステップでは、テキストプロンプトから画像を生成し、ブラウザ上に表示するところまで実装しました。しかし、URLから取得した画像は1時間しか有効ではなく、せっかく気に入った画像も消えてしまいます。
今回のステップでは、生成した画像をローカルのパソコンに保存できるようにして、いつでも見返せるようにしましょう。
Base64形式での画像データ取得
まず、OpenAI APIから画像を取得する時に、URLではなくBase64エンコードされたデータとして受け取るように設定します。
「Base64って何?」と思った方のために簡単に説明すると、Base64は画像などのバイナリデータをテキスト形式に変換する方法です。これによって、画像データをテキストとして扱えるようになります。
app.pyファイルを開いて、以下のように修正しましょう
import streamlit as st
from openai import OpenAI
import json
import base64
from pathlib import Path
import time
from datetime import datetime
# アプリのタイトルとガイド
st.title("AIアートスタジオ🎨")
st.write("あなたの言葉から絵を描くAIアプリです。下のフォームに描いて欲しいものを入力してください!")
# 保存先ディレクトリの設定
SAVE_DIR = Path.cwd() / "generated_images"
SAVE_DIR.mkdir(exist_ok=True) # ディレクトリがなければ作成
# プロンプトの例を表示
st.subheader("プロンプトの例:")
examples = [
"浮世絵風の富士山と桜",
"未来都市の東京タワー",
"猫が経営する和風カフェ",
"雪の中の金閣寺"
]
example_text = " / ".join(examples)
st.write(example_text)
# OpenAIクライアントの初期化
client = OpenAI()
# モデル選択
model = st.radio("モデル", ["DALL-E 2", "DALL-E 3"], index=0, horizontal=True, key="model_radio")
model_name = "dall-e-2" if model == "DALL-E 2" else "dall-e-3"
# モデルによって利用可能なサイズが異なる
if model == "DALL-E 2":
size_options = ["256x256", "512x512", "1024x1024"]
default_size = "512x512"
else: # DALL-E 3
size_options = ["1024x1024", "1024x1792", "1792x1024"]
default_size = "1024x1024"
# 画像生成設定
col1, col2 = st.columns([3, 1])
with col1:
prompt = st.text_input("描いて欲しいものを入力してください",
value="和風の庭園と金閣寺",
key="prompt_input")
with col2:
size = st.selectbox("画像サイズ",
options=size_options,
index=size_options.index(default_size),
key="size_select")
# 生成ボタンが押されたら画像を生成
if st.button("画像を生成する✨", key="generate_button"):
with st.spinner("AIが画像を生成中...少々お待ちください"):
try:
# OpenAIのAPIを呼び出して画像を生成(Base64形式で取得)
response = client.images.generate(
model=model_name,
prompt=prompt,
n=1,
size=size,
response_format="b64_json", # Base64形式で画像データを取得
)
# ファイル名用に現在時刻を取得(時分秒まで)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# Base64データをデコードして画像を保存
image_data = base64.b64decode(response.data[0].b64_json)
# プロンプトの最初の10文字をファイル名に使用(日本語もOK)
# 長すぎるとファイル名が扱いにくくなるので適度に切る
short_prompt = prompt[:10].replace(" ", "_")
image_file = SAVE_DIR / f"{short_prompt}_{timestamp}.png"
# 画像ファイルを保存
with open(image_file, mode="wb") as f:
f.write(image_data)
# 保存した画像を表示
st.image(image_file, caption=f"プロンプト: {prompt}", use_container_width=True)
# 保存場所を表示
st.success(f"画像を保存しました: {image_file}")
# JSONレスポンスも保存しておく(必要に応じて)
json_file = SAVE_DIR / f"{short_prompt}_{timestamp}.json"
with open(json_file, mode="w", encoding="utf-8") as f:
json.dump(response.to_dict(), f, ensure_ascii=False, indent=2)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
st.warning("APIキーの設定や入力内容を確認してください。不適切な内容の画像は生成できません。")このコードは前のステップから以下の点を変更しています:
- Base64形式でデータを取得:
response_format="b64_json"を追加し、URLではなく直接画像データを取得するようにしました。 - 保存用のディレクトリ設定:
SAVE_DIRとしてgenerated_imagesフォルダを指定しました。存在しない場合は自動的に作成します。 - 画像データの保存: Base64エンコードされたデータをデコードして、PNGファイルとして保存します。
- ファイル名の工夫: タイムスタンプとプロンプトの一部を使ってユニークなファイル名を生成します。
- JSON形式でのレスポンス保存: 画像だけでなく、APIレスポンス全体もJSONファイルとして保存しています。
Base64エンコードとは?
少し技術的な話になりますが、Base64エンコードについて詳しく知りたい方のために説明します。
Base64エンコードは、バイナリデータ(画像などのコンピュータが扱う生データ)をテキスト形式に変換する方法です。具体的には、0と1のデータを、A-Z、a-z、0-9、+、/という64種類の文字で表現します。
例えば、「こんにちは」という文字をBase64エンコードすると「44GT44KT44Gr44Gh44Gv」のような文字列になります。このようにエンコードすることで、どんなデータでもテキストとして扱えるようになります。
画像の場合、このBase64エンコードされたテキストは非常に長くなります。例えば、小さな画像でも数万文字になることがあります。これをデコード(元に戻す)すると、元の画像データになります。
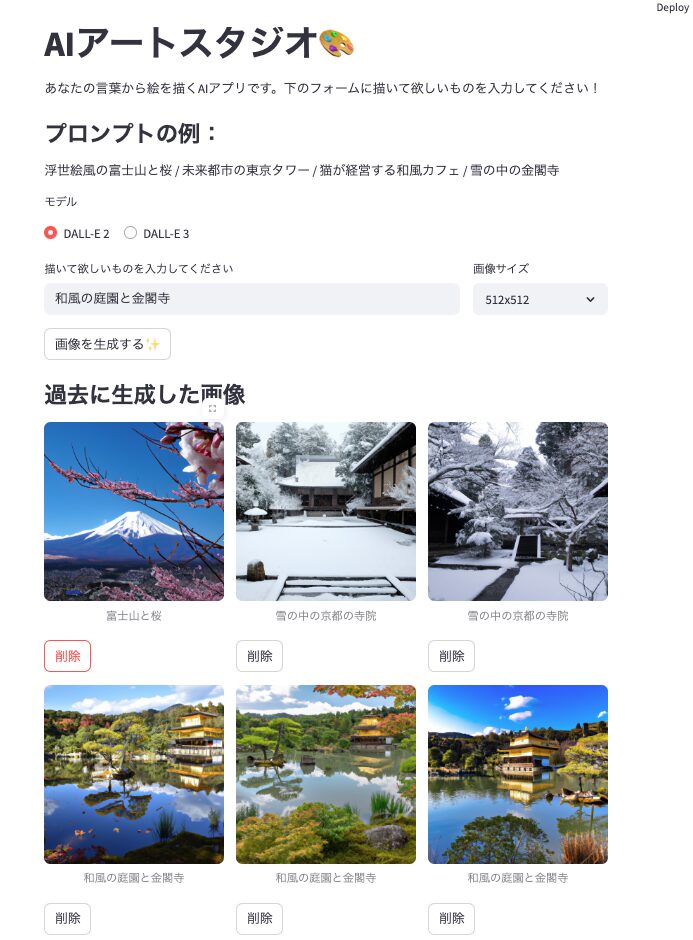
保存した画像の管理機能を追加
せっかく画像を保存できるようになったので、過去に生成した画像を一覧表示する機能も追加してみましょう。以下のコードをapp.pyの最後に追加しますた画像を一覧表示する機能も追加してみましょう。以下のコードをapp.pyの最後に追加します:
# 過去の生成画像を表示するセクション
st.subheader("過去に生成した画像")
# 画像ファイルを検索
image_files = list(SAVE_DIR.glob("*.png"))
if not image_files:
st.write("まだ画像が生成されていません。上のフォームから画像を生成してみましょう!")
else:
# 最新の画像を先頭に表示するために並べ替え
image_files.sort(key=lambda x: x.stat().st_mtime, reverse=True)
# 画像を3列のグリッドで表示
cols = st.columns(3)
for i, image_file in enumerate(image_files):
# ファイル名からプロンプト部分を抽出(最初の部分)
prompt_part = image_file.stem.split("_")[0].replace("_", " ")
# 画像を表示
with cols[i % 3]:
st.image(image_file, caption=prompt_part, use_container_width=True)
# ファイル削除ボタン(オプション)
if st.button(f"削除", key=f"delete_button_{i}"):
image_file.unlink() # ファイルを削除
# 対応するJSONファイルも削除
json_file = SAVE_DIR / f"{image_file.stem}.json"
if json_file.exists():
json_file.unlink()
st.rerun() # ページを再読み込みこの追加コードでは:
- 生成済み画像の検索:
generated_imagesフォルダ内のPNGファイルを検索します。 - 最新順に並べ替え: ファイルの更新日時を基準に並べ替えて、最新の画像を先頭に表示します。
- グリッド表示: 3列のグリッドレイアウトで画像を整理して表示します。
- 削除機能: 不要になった画像を削除するボタンも追加しています。各ボタンに一意のキーを設定しています。
複数画像の生成
DALL-Eでは一度に複数の画像を生成することもできます。選択肢が欲しい場合に便利ですね。以下のように、画像の生成数を選べるオプションを追加してみましょう
# 複数画像生成の設定
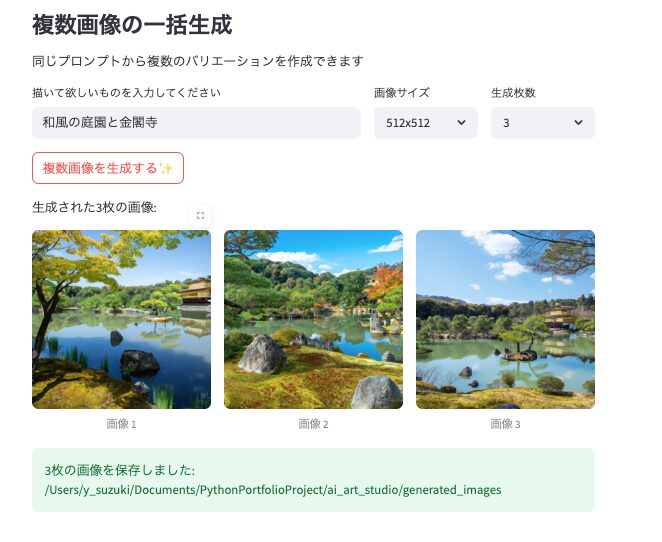
st.subheader("複数画像の一括生成")
st.write("同じプロンプトから複数のバリエーションを作成できます")
# 画像生成設定
col1, col2, col3 = st.columns([3, 1, 1])
with col1:
multi_prompt = st.text_input("描いて欲しいものを入力してください",
value="和風の庭園と金閣寺",
key="multi_prompt_input")
with col2:
multi_size = st.selectbox("画像サイズ",
options=size_options,
index=size_options.index(default_size),
key="multi_size_select")
with col3:
n_images = st.selectbox("生成枚数",
options=[1, 2, 3, 4],
index=0,
key="n_images_select") # デフォルトは1枚
# 生成ボタンが押されたら画像を生成
if st.button("複数画像を生成する✨", key="multi_generate_button"):
with st.spinner(f"AIが{n_images}枚の画像を生成中...少々お待ちください"):
try:
# OpenAIのAPIを呼び出して画像を生成(Base64形式で取得)
response = client.images.generate(
model=model_name,
prompt=multi_prompt,
n=n_images, # 選択した枚数の画像を生成
size=multi_size,
response_format="b64_json", # Base64形式で画像データを取得
)
# タイムスタンプ(すべての画像で共通)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
short_prompt = multi_prompt[:10].replace(" ", "_")
# 画像を表示するためのコンテナ
st.write(f"生成された{n_images}枚の画像:")
image_cols = st.columns(min(n_images, 3)) # 最大3列
# 各画像を処理
for i, image_data in enumerate(response.data):
# Base64データをデコード
decoded_image = base64.b64decode(image_data.b64_json)
# 画像ファイルを保存
image_file = SAVE_DIR / f"{short_prompt}_{timestamp}_{i+1}.png"
with open(image_file, mode="wb") as f:
f.write(decoded_image)
# 画像を表示
col_index = i % min(n_images, 3) # 3列以内に収める
with image_cols[col_index]:
st.image(image_file, caption=f"画像 {i+1}", use_container_width=True)
# 保存場所を表示
st.success(f"{n_images}枚の画像を保存しました: {SAVE_DIR}")
# JSONレスポンスも保存
json_file = SAVE_DIR / f"{short_prompt}_{timestamp}.json"
with open(json_file, mode="w", encoding="utf-8") as f:
json.dump(response.to_dict(), f, ensure_ascii=False, indent=2)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
st.warning("APIキーの設定や入力内容を確認してください。不適切な内容の画像は生成できません。")このコードでは、生成する画像の枚数を選択できるようになっています。最大4枚まで選べます(コスト節約のため)。生成された画像は並べて表示され、それぞれが個別のファイルとして保存されます。各UI要素には一意のキーを設定し、重複エラーを防いでいます。
Base64エンコードの利点
画像をBase64形式で取得する利点は以下の通りです:
- 永続的な保存: URLは1時間しか有効ではありませんが、Base64データは永続的に保存できます。
- サーバーに依存しない: 一度データを取得してしまえば、OpenAIのサーバーがダウンしても画像を見ることができます。
- プログラム内での処理: Base64データは、別の画像処理ライブラリに直接渡して加工することもできます。
- セキュリティ: 非公開画像を扱う場合、URLよりもローカル保存の方がセキュリティ上安全な場合があります。
まとめると、このステップでは:
- Base64形式での画像取得: URLではなく画像のバイナリデータを直接取得
- ローカルへの保存: 生成した画像をファイルとして保存
- 画像の管理機能: 過去に生成した画像の閲覧と削除
- 複数画像の生成: 一度に複数のバリエーションを生成
これらの機能により、AIで生成した画像を効率的に保存・管理できるようになりました!次のステップでは、生成した画像のバリエーションを作成する機能を実装します。エーションを作成する機能を実装します。
Step 4: 生成画像からバリエーションを作る
前のステップまでで、テキストプロンプトから画像を生成し、ローカルに保存する機能が完成しました。でも、「イメージに近いけど、もう少し違う感じにしたい…」と思ったことはありませんか?
このステップでは、既に生成した画像を元に新しいバリエーションを作成する機能を追加します。これは「この画像の雰囲気は好きだけど、少し変化が欲しい」というときにとても便利な機能です!
画像バリエーション生成の仕組み
OpenAIのDALL-E 2モデルには、既存の画像から新しいバリエーションを生成する機能があります。これは元の画像の特徴や雰囲気を保ちながら、少し違った表現の画像を作り出せるものです。例えるなら、「もう一度サイコロを振る」ような感覚でしょうか。
それでは、この機能をStreamlitアプリに追加してみましょう。
バリエーション生成機能の実装
app.pyファイルに、以下のコードを追加します。これは前のステップで作成した「過去に生成した画像」の表示部分を拡張したものです。
# 過去の生成画像を表示するセクション
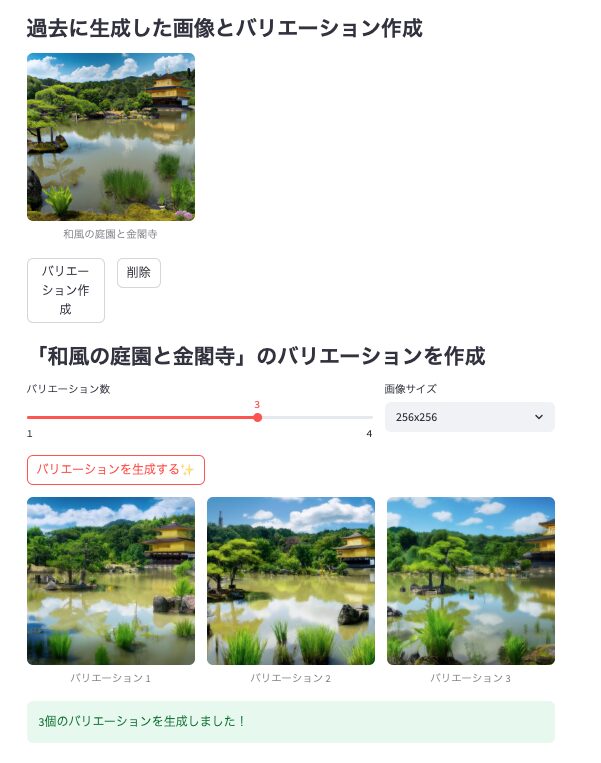
st.subheader("過去に生成した画像とバリエーション作成")
# 画像ファイルを検索
image_files = list(SAVE_DIR.glob("*.png"))
if not image_files:
st.write("まだ画像が生成されていません。上のフォームから画像を生成してみましょう!")
else:
# 最新の画像を先頭に表示するために並べ替え
image_files.sort(key=lambda x: x.stat().st_mtime, reverse=True)
# セッション状態を使って選択された画像を保存
if 'selected_image' not in st.session_state:
st.session_state.selected_image = None
# 画像を3列のグリッドで表示
cols = st.columns(3)
for i, image_file in enumerate(image_files):
# ファイル名からプロンプト部分を抽出(最初の部分)
prompt_part = image_file.stem.split("_")[0].replace("_", " ")
# 画像を表示
with cols[i % 3]:
st.image(image_file, caption=prompt_part, use_container_width=True)
# バリエーション作成と削除のボタンを横に並べる
button_cols = st.columns(2)
# バリエーション作成ボタン
with button_cols[0]:
if st.button("バリエーション作成", key=f"vary_button_{i}"):
st.session_state.selected_image = str(image_file)
st.rerun()
# ファイル削除ボタン
with button_cols[1]:
if st.button("削除", key=f"delete_button_{i}"):
image_file.unlink() # ファイルを削除
# 対応するJSONファイルも削除
json_file = SAVE_DIR / f"{image_file.stem}.json"
if json_file.exists():
json_file.unlink()
st.rerun() # ページを再読み込み
# バリエーション作成が選択された場合の処理
if st.session_state.selected_image:
selected_image = Path(st.session_state.selected_image)
st.subheader(f"「{selected_image.stem.split('_')[0].replace('_', ' ')}」のバリエーションを作成")
# バリエーション設定
var_cols = st.columns([2, 1])
with var_cols[0]:
n_variations = st.slider("バリエーション数", min_value=1, max_value=4, value=3, key="variation_count")
with var_cols[1]:
# DALL-E 2でのみバリエーション作成可能
var_size = st.selectbox("画像サイズ",
options=["256x256", "512x512", "1024x1024"],
index=0,
key="variation_size")
# 実行ボタン
if st.button("バリエーションを生成する✨", key="generate_variations_button"):
with st.spinner(f"{n_variations}個のバリエーションを生成中..."):
try:
# 画像ファイルを開く
with open(selected_image, "rb") as img_file:
img_data = img_file.read()
# 画像バリエーション生成API呼び出し(DALL-E 2のみ対応)
if model == "DALL-E 3":
st.warning("バリエーション作成はDALL-E 2でのみ利用可能です。一時的にDALL-E 2を使用します。")
response = client.images.create_variation(
image=img_data, # バイナリデータを直接渡す
n=n_variations,
size=var_size,
response_format="b64_json",
)
# 結果表示用のカラムを作成
result_cols = st.columns(min(n_variations, 3))
# タイムスタンプを取得
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# 生成元の画像名から識別子を取得
original_name = selected_image.stem.split("_")[0]
# 各バリエーション画像を処理
for i, img_data in enumerate(response.data):
# Base64データをデコード
decoded_image = base64.b64decode(img_data.b64_json)
# ファイル名を作成(元の画像名を基に)
var_filename = f"{original_name}_var{i+1}_{timestamp}.png"
var_file = SAVE_DIR / var_filename
# 画像を保存
with open(var_file, "wb") as f:
f.write(decoded_image)
# 画像を表示
with result_cols[i % min(n_variations, 3)]:
st.image(var_file, caption=f"バリエーション {i+1}", use_container_width=True)
# 成功メッセージ
st.success(f"{n_variations}個のバリエーションを生成しました!")
# JSONレスポンスも保存
json_file = SAVE_DIR / f"{original_name}_variations_{timestamp}.json"
with open(json_file, "w", encoding="utf-8") as f:
json.dump(response.to_dict(), f, ensure_ascii=False, indent=2)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
if "File is too large" in str(e):
st.warning("画像サイズが大きすぎます。4MB以下の画像を使用してください。")
elif "must be square" in str(e):
st.warning("画像は正方形である必要があります。")
else:
st.warning("APIキーの設定や画像形式を確認してください。")# 過去の生成画像を表示するセクション
st.subheader("過去に生成した画像とバリエーション作成")
# 画像ファイルを検索
image_files = list(SAVE_DIR.glob("*.png"))
if not image_files:
st.write("まだ画像が生成されていません。上のフォームから画像を生成してみましょう!")
else:
# 最新の画像を先頭に表示するために並べ替え
image_files.sort(key=lambda x: x.stat().st_mtime, reverse=True)
# セッション状態を使って選択された画像を保存
if 'selected_image' not in st.session_state:
st.session_state.selected_image = None
# 画像を3列のグリッドで表示
cols = st.columns(3)
for i, image_file in enumerate(image_files):
# ファイル名からプロンプト部分を抽出(最初の部分)
prompt_part = image_file.stem.split("_")[0].replace("_", " ")
# 画像を表示
with cols[i % 3]:
st.image(image_file, caption=prompt_part, use_container_width=True)
# バリエーション作成と削除のボタンを横に並べる
button_cols = st.columns(2)
# バリエーション作成ボタン
with button_cols[0]:
if st.button("バリエーション作成", key=f"vary_button_{i}"):
st.session_state.selected_image = str(image_file)
st.rerun()
# ファイル削除ボタン
with button_cols[1]:
if st.button("削除", key=f"delete_button_{i}"):
image_file.unlink() # ファイルを削除
# 対応するJSONファイルも削除
json_file = SAVE_DIR / f"{image_file.stem}.json"
if json_file.exists():
json_file.unlink()
st.rerun() # ページを再読み込み
# バリエーション作成が選択された場合の処理
if st.session_state.selected_image:
selected_image = Path(st.session_state.selected_image)
st.subheader(f"「{selected_image.stem.split('_')[0].replace('_', ' ')}」のバリエーションを作成")
# バリエーション設定
var_cols = st.columns([2, 1])
with var_cols[0]:
n_variations = st.slider("バリエーション数", min_value=1, max_value=4, value=3, key="variation_count")
with var_cols[1]:
var_size = st.selectbox("画像サイズ",
options=["256x256", "512x512"],
index=0,
key="variation_size")
# 実行ボタン
if st.button("バリエーションを生成する✨", key="generate_variations_button"):
with st.spinner(f"{n_variations}個のバリエーションを生成中..."):
try:
# 画像ファイルを開く
with open(selected_image, "rb") as img_file:
img_data = img_file.read()
# バリエーション生成API呼び出し
response = client.images.create_variation(
image=img_data, # バイナリデータを直接渡す
n=n_variations,
size=var_size,
response_format="b64_json",
)
# 結果表示用のカラムを作成
result_cols = st.columns(min(n_variations, 3))
# タイムスタンプを取得
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# 生成元の画像名から識別子を取得
original_name = selected_image.stem.split("_")[0]
# 各バリエーション画像を処理
for i, img_data in enumerate(response.data):
# Base64データをデコード
decoded_image = base64.b64decode(img_data.b64_json)
# ファイル名を作成(元の画像名を基に)
var_filename = f"{original_name}_var{i+1}_{timestamp}.png"
var_file = SAVE_DIR / var_filename
# 画像を保存
with open(var_file, "wb") as f:
f.write(decoded_image)
# 画像を表示
with result_cols[i % min(n_variations, 3)]:
st.image(var_file, caption=f"バリエーション {i+1}", use_container_width=True)
# 成功メッセージ
st.success(f"{n_variations}個のバリエーションを生成しました!")
# JSONレスポンスも保存
json_file = SAVE_DIR / f"{original_name}_variations_{timestamp}.json"
with open(json_file, "w", encoding="utf-8") as f:
json.dump(response.to_dict(), f, ensure_ascii=False, indent=2)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
if "File is too large" in str(e):
st.warning("画像サイズが大きすぎます。4MB以下の画像を使用してください。")
elif "must be square" in str(e):
st.warning("画像は正方形である必要があります。")
else:
st.warning("APIキーの設定や画像形式を確認してください。")このコードでは、以下のことを実装しています:
- バリエーション作成ボタンの追加: 各画像の下に「バリエーション作成」ボタンを追加しました。
- バリエーション数とサイズの設定: ユーザーがバリエーション数(1〜4枚)とサイズを選択できます。
- OpenAIのバリエーション生成API呼び出し:
create_variationメソッドを使って、選択した画像のバリエーションを生成します。 - 生成したバリエーションの保存と表示: 生成した各バリエーションを保存し、画面に表示します。
Step 5: 使いやすいUIに改良する(オプション)
ここまでのステップで基本的なAIアートスタジオの機能は完成しました。しかし現状では単に機能を積み上げただけなので、実際のアプリケーションとしては使いづらい面があります。このステップでは、実用的なUIに改良するためのアイデアを紹介します。
このステップはオプションです。基本機能の理解が目的の方は、ここまでの内容だけでも十分実用的なアプリを作ることができます。
UI改善のアイデア
1. タブインターフェースの導入
現在はすべての機能が一つのページに積み重なっているため、ページが長くなりスクロールが必要になります。Streamlitのst.tabsを使ってタブインターフェースに変更すると、機能ごとに整理され使いやすくなります。
import streamlit as st
from openai import OpenAI
import json
import base64
from pathlib import Path
import time
from datetime import datetime
# アプリのタイトルと説明
st.title("AIアートスタジオ🎨")
st.write("テキストから画像を生成したり、画像のバリエーションを作成できるアプリです")
# 保存先ディレクトリの設定
SAVE_DIR = Path.cwd() / "generated_images"
SAVE_DIR.mkdir(exist_ok=True)
# OpenAIクライアントの初期化
client = OpenAI()
# タブの作成
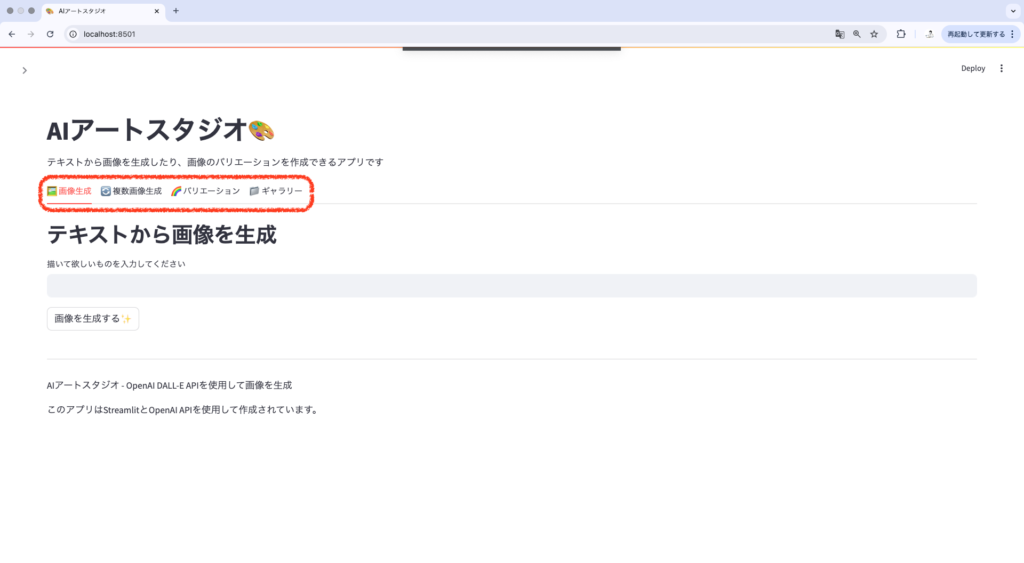
tab1, tab2, tab3 = st.tabs(["🖼️ 画像生成", "🔄 複数画像生成", "📁 保存画像とバリエーション"])
# タブ1: 基本的な画像生成
with tab1:
st.header("テキストから画像を生成")
# 以下、ステップ2の画像生成コード...
# タブ2: 複数画像の一括生成
with tab2:
st.header("複数画像の一括生成")
# 以下、ステップ3の複数画像生成コード...
# タブ3: 保存画像の管理とバリエーション
with tab3:
st.header("保存画像とバリエーション作成")
# 以下、ステップ3と4の画像管理・バリエーション生成コード...このように機能ごとにタブを分けることで:
- ユーザーは必要な機能だけに集中できる
- 画面のスクロールが少なくなり、操作性が向上する
- 機能の追加・拡張がしやすくなる
2. サイドバーの活用
Streamlitのサイドバーを使うと、設定項目や補助的な機能を本体から分離できます。これにより、メイン画面はコンテンツに集中させることができます。
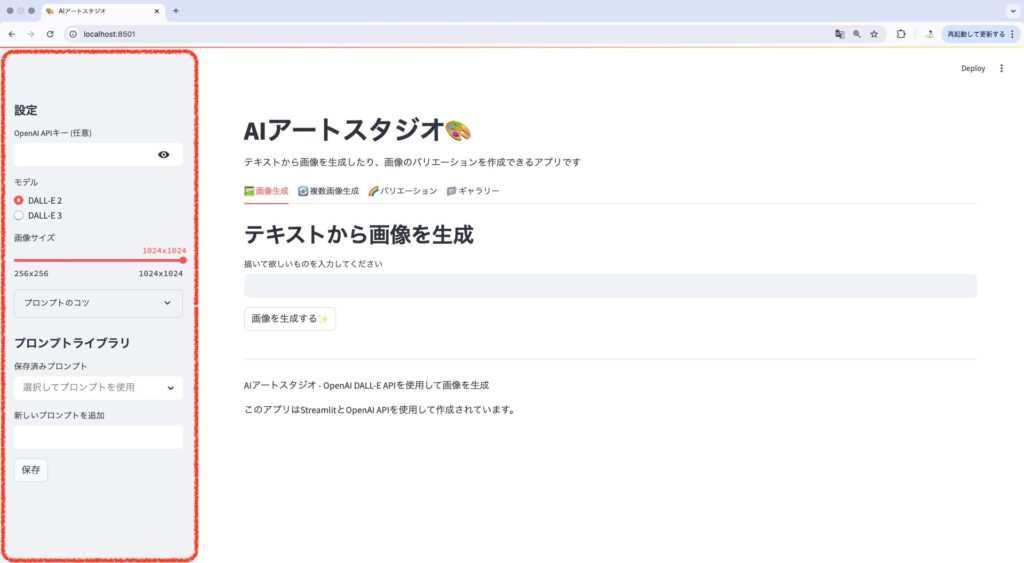
# サイドバーに設定項目を配置
with st.sidebar:
st.header("設定")
# モデル選択(DALL-E 2またはDALL-E 3)
model = st.radio("モデル", ["DALL-E 2", "DALL-E 3"], index=0)
# モデルによって利用可能なサイズが異なる
if model == "DALL-E 2":
size_options = ["256x256", "512x512", "1024x1024"]
default_size = "512x512"
else: # DALL-E 3
size_options = ["1024x1024", "1024x1792", "1792x1024"]
default_size = "1024x1024"
size = st.select_slider("画像サイズ", options=size_options, value=default_size)
# プロンプトのヒント表示
with st.expander("プロンプトのコツ"):
st.write("""
- 具体的に描写する
- アーティスト名や画風を指定する
- 色や構図を指定する
- 日本語と英語を組み合わせる
""")
# APIキー設定(オプション)
with st.expander("APIキー設定"):
api_key = st.text_input("OpenAI APIキー (任意)", type="password")
if api_key:
st.session_state.api_key = api_key
st.success("APIキーが設定されました")
# メイン画面のコードでサイドバーの設定を使用
# 例: client.images.generate(model="dall-e-2" if model == "DALL-E 2" else "dall-e-3", size=size, ...)サイドバーを活用することで:
- 設定項目がまとまり、視覚的に整理される
- メイン画面のスペースを有効活用できる
- ユーザーが常に設定を確認・変更できる
3. プロンプトライブラリ機能
良いプロンプトを保存して再利用できる機能を追加すると、ユーザー体験が向上します。
# セッション状態にプロンプトライブラリを初期化
if 'prompt_library' not in st.session_state:
st.session_state.prompt_library = [
"浮世絵風の富士山と桜",
"未来都市の東京タワー",
"猫が経営する和風カフェ",
]
# サイドバーにプロンプトライブラリを表示
with st.sidebar:
st.header("プロンプトライブラリ")
# 保存済みプロンプトの表示と選択
selected_prompt = st.selectbox(
"保存済みプロンプト",
st.session_state.prompt_library,
index=None,
placeholder="選択してプロンプトを使用"
)
# 新しいプロンプトの追加
new_prompt = st.text_input("新しいプロンプトを追加")
if st.button("保存", key="save_prompt") and new_prompt:
if new_prompt not in st.session_state.prompt_library:
st.session_state.prompt_library.append(new_prompt)
st.success("プロンプトを保存しました")
st.rerun()
# メイン画面でプロンプト入力時に選択されたプロンプトを表示
if selected_prompt:
prompt_input = st.text_input("描いて欲しいものを入力してください",
value=selected_prompt,
key="main_prompt")
else:
prompt_input = st.text_input("描いて欲しいものを入力してください",
key="main_prompt")プロンプトライブラリの利点:
- 成功したプロンプトを保存して再利用できる
- 共有や再現性が向上する
- 初心者ユーザーが参考にできる
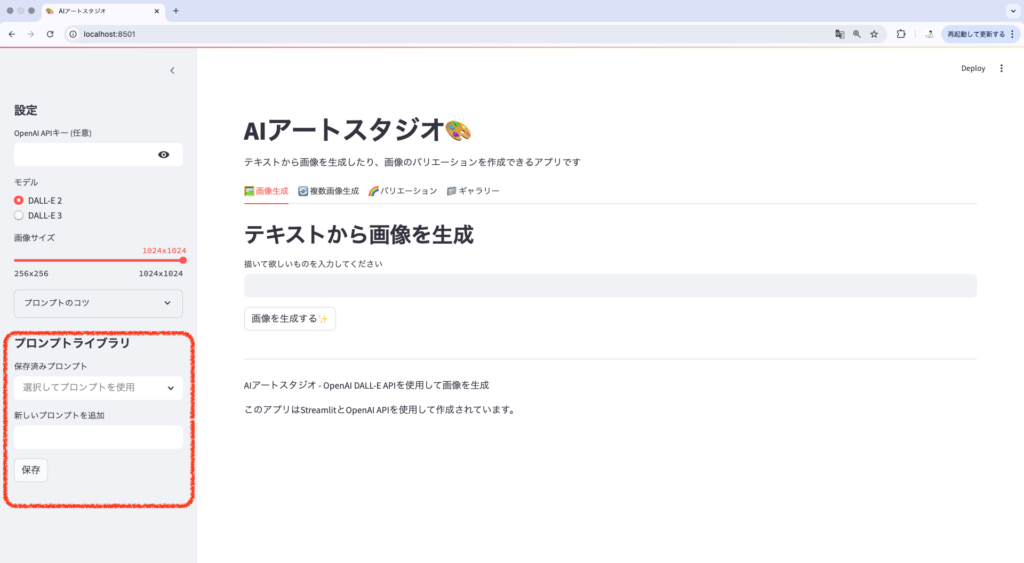
4. ドラッグ&ドロップでの画像アップロード
既存の画像からバリエーションを作成するときに、ファイルアップロード機能を追加すると便利です。
# バリエーション作成タブに画像アップロード機能を追加
with tab3:
st.header("外部画像からバリエーションを作成")
uploaded_file = st.file_uploader("画像をアップロード", type=["png", "jpg", "jpeg"])
if uploaded_file is not None:
# 画像のプレビュー表示
st.image(uploaded_file, caption="アップロードされた画像", use_container_width=True)
# バリエーション設定
n_variations = st.slider("バリエーション数", min_value=1, max_value=4, value=3, key="upload_var_count")
var_size = st.selectbox("画像サイズ",
options=["256x256", "512x512", "1024x1024"],
index=0,
key="upload_var_size")
# バリエーション生成ボタン
if st.button("バリエーションを生成", key="upload_var_button"):
with st.spinner("バリエーションを生成中..."):
try:
# 正方形に変換する処理(必要な場合)
from PIL import Image
import io
# 画像を読み込み
image = Image.open(uploaded_file)
# 正方形にリサイズ(短い辺に合わせる)
min_dim = min(image.width, image.height)
left = (image.width - min_dim) // 2
top = (image.height - min_dim) // 2
right = left + min_dim
bottom = top + min_dim
square_image = image.crop((left, top, right, bottom))
# 一時ファイルに保存
img_byte_arr = io.BytesIO()
square_image.save(img_byte_arr, format='PNG')
img_byte_arr.seek(0)
# バリエーション生成APIを呼び出し
response = client.images.create_variation(
image=img_byte_arr,
n=n_variations,
size=var_size,
response_format="b64_json",
)
# 以下、バリエーション画像の保存と表示の処理...
except Exception as e:
st.error(f"エラーが発生しました: {e}")
# エラーの種類に応じたメッセージ表示...外部画像のアップロード機能を追加することで:
- 他のソースで作成した画像のバリエーションを作れる
- ユーザー所有の写真をAIで変化させることができる
- アプリの用途が広がる
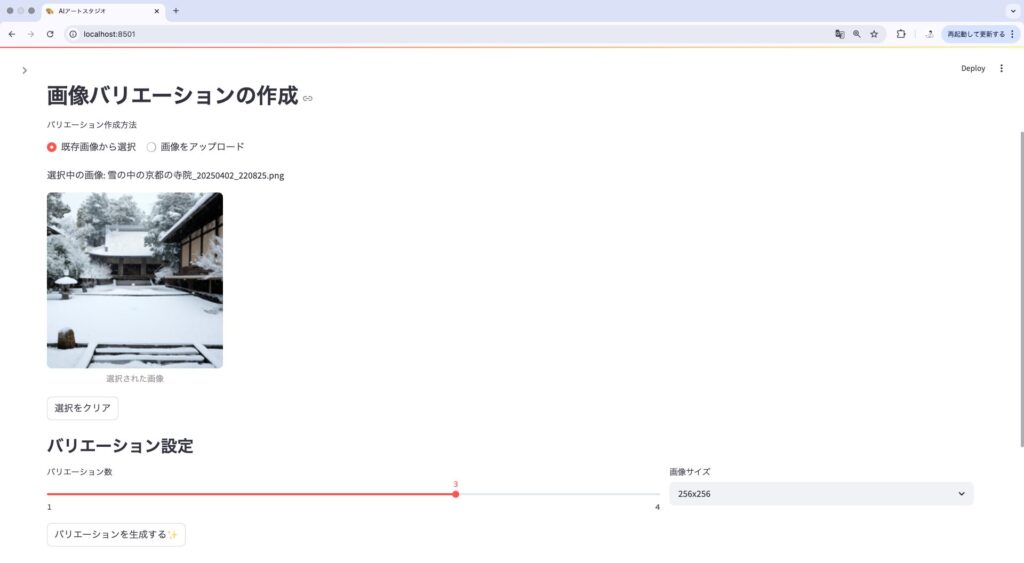
5. ギャラリー表示とお気に入り機能
生成した画像をギャラリー形式で表示し、お気に入り機能を追加すると整理しやすくなります。
# タブ3にギャラリー表示とお気に入り機能を追加
with tab3:
st.header("生成画像ギャラリー")
# 表示モード選択
view_mode = st.radio("表示", ["すべての画像", "お気に入りのみ"], horizontal=True)
# セッション状態にお気に入りリストを初期化
if 'favorites' not in st.session_state:
st.session_state.favorites = set()
# 画像ファイルを検索
image_files = list(SAVE_DIR.glob("*.png"))
if not image_files:
st.write("まだ画像が生成されていません。")
else:
# 最新の画像を先頭に表示
image_files.sort(key=lambda x: x.stat().st_mtime, reverse=True)
# お気に入りフィルター
if view_mode == "お気に入りのみ":
image_files = [img for img in image_files if str(img) in st.session_state.favorites]
if not image_files:
st.write("お気に入りに追加された画像はありません。")
# グリッドレイアウトの列数を選択(レスポンシブデザイン)
cols_per_row = st.select_slider("列数", options=[2, 3, 4], value=3)
# 画像を表示するグリッド
cols = st.columns(cols_per_row)
for i, image_file in enumerate(image_files):
prompt_part = image_file.stem.split("_")[0].replace("_", " ")
col_idx = i % cols_per_row
with cols[col_idx]:
st.image(image_file, caption=prompt_part, use_container_width=True)
# お気に入りと操作ボタン
btn_cols = st.columns([1, 1, 1])
with btn_cols[0]:
# お気に入りボタン
is_favorite = str(image_file) in st.session_state.favorites
fav_label = "★" if is_favorite else "☆"
if st.button(fav_label, key=f"fav_{i}"):
if is_favorite:
st.session_state.favorites.remove(str(image_file))
else:
st.session_state.favorites.add(str(image_file))
st.rerun()
with btn_cols[1]:
# バリエーションボタン
if st.button("🔄", key=f"vary_{i}"):
st.session_state.selected_image = str(image_file)
st.rerun()
with btn_cols[2]:
# 削除ボタン
if st.button("🗑️", key=f"del_{i}"):
# 削除処理...
if str(image_file) in st.session_state.favorites:
st.session_state.favorites.remove(str(image_file))
st.rerun()ギャラリー表示とお気に入り機能の利点:
- 生成した画像を効率的に整理・管理できる
- 重要な画像とそうでないものを区別できる
- アイコンでボタンを表示することでUIがすっきりする
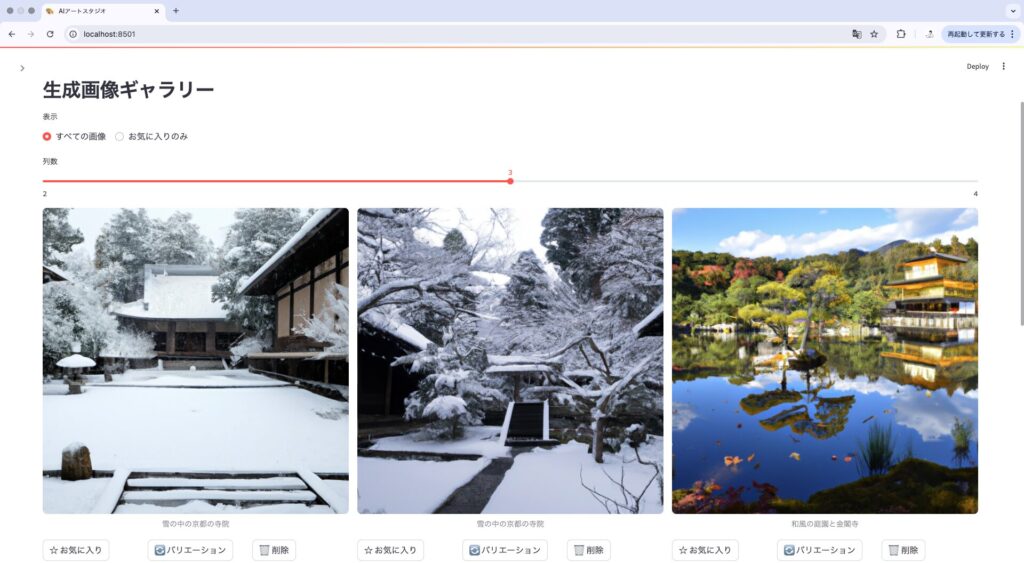
UI改善のポイント
これらの改良を行う際に考慮すべき重要なポイントをいくつか紹介します
- 一貫性のあるデザイン:UI要素の配置や色、アイコンなどに一貫性を持たせることで、使いやすさが向上します。
- エラー処理の強化:すべての例外を適切に処理し、ユーザーにわかりやすいエラーメッセージを表示します。
- ローディング表示の改良:画像生成中のローディング表示をより視覚的にわかりやすくします。
- レスポンシブデザイン:様々な画面サイズに対応できるようにレイアウトを調整します。
- 状態管理の改善:
st.session_stateを活用して、ユーザーの操作状態を適切に保持します。
このステップでは、基本機能を持ったAIアートスタジオを実用的なアプリケーションに変えるためのUI改善アイデアを紹介しました。これらの改良は個別に実装することもできますし、複数組み合わせることでさらに使いやすいアプリにすることもできます。
UI改良の最も重要な点は、ユーザーの使いやすさを最優先に考えることです。美しいデザインも大切ですが、直感的に操作できることがより重要です。
このアプリを実際のポートフォリオとして活用する場合は、これらのUI改善を取り入れて、あなたのデザインセンスやユーザー体験への配慮を示すことができるでしょう。り上げてください。UIデザインはユーザー体験を左右する重要な要素です。何度も試行錯誤しながら、使いやすさとデザイン性のバランスを探求していきましょう!
まとめ
このプロジェクトを通じて、最先端のAI技術をPythonで扱う方法を学びました。特に以下のスキルと知識を習得することができました:
習得したスキル
- OpenAI APIの活用
- APIキーの取得と適切な管理方法
- OpenAI Python ライブラリの使用方法
- APIリクエストとレスポンスの処理
- AIプロンプトエンジニアリング
- 効果的な画像生成プロンプトの作成テクニック
- DALL-Eモデルの特性と使い分け
- 画像生成パラメータの最適化
- データ変換と処理
- Base64エンコードデータの取り扱い
- JSONレスポンスからの情報抽出
- バイナリデータの処理とファイル保存
- Streamlitによるアプリ開発
- インタラクティブなWebインターフェースの構築
- ユーザー入力の処理とバリデーション
- 非同期処理とローディング表示
- エラーハンドリング
- 例外処理とユーザーフレンドリーなエラーメッセージ
- API制限やポリシー対応
- 堅牢なアプリケーション設計
作成したもの
このプロジェクトの成果物として、以下の機能を持つAIアートスタジオアプリが完成しました:
- テキストプロンプトから画像を生成する機能
- 複数の画像を一括生成する機能
- 生成した画像をローカルに保存する機能
- 既存画像からバリエーションを作成する機能
- 保存した画像を管理するギャラリー機能
ポートフォリオとしての価値
このプロジェクトは単なる学習教材ではなく、実用的なポートフォリオとして活用できます:
- 技術的な多様性:フロントエンド(Streamlit)からバックエンド(OpenAI API)まで幅広い技術を使用
- 問題解決能力:API連携、データ変換、ファイル操作など複数の課題を解決
- 最新技術への理解:AIと画像生成という最先端技術を実用レベルで実装
- 完成度の高さ:エラー処理やUI/UXにも配慮した本格的なアプリケーション
発展させる方法
このプロジェクトをベースに、さらに以下のような機能を追加してあなただけのオリジナルポートフォリオに発展させることができます:
- 画像編集機能(フィルター適用、テキスト追加など)
- SNS共有機能の実装
- 画像生成履歴の保存と分析
- プロンプト自動生成機能(AI支援によるプロンプト作成)
- デプロイして公開サービス化(Streamlit Cloud, Heroku, AWS等)
このプロジェクトで身につけたスキルは、AIを活用したアプリケーション開発において非常に価値があります。これらの経験は、副業や転職活動において、あなたの技術力とクリエイティビティを証明する強力な武器となるでしょう。
ぜひこのプロジェクトをカスタマイズして、あなただけのオリジナル作品に仕上げてみてください。完成したアプリのURLを共有して、技術力をアピールすることができます。

本コンテンツへの意見や質問