
Step5:折れ線グラフ(plotly,go)の作成
1.必要なモジュールの追加
まず、plotlyモジュールを追加します。requirements.txtファイルを開き、以下の行を追加してください:
plotly==5.24.0次に、ターミナルで以下のコマンドを実行してパッケージをインストールします:
pip install -r requirements.txtそして、app.pyファイルの先頭に以下の行を追加します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go2. データの準備
折れ線グラフ用のサンプルデータを作成します。
st.header('レッスン5: 折れ線グラフ(plotly,go)の作成')
# サンプルデータの作成
data = {
'月': ['1月', '2月', '3月', '4月', '5月', '6月'],
'売上': [100, 120, 140, 180, 200, 210],
'利益': [20, 25, 30, 40, 50, 55]
}
df = pd.DataFrame(data)
st.write('サンプルデータ:')
st.dataframe(df)アプリ画面

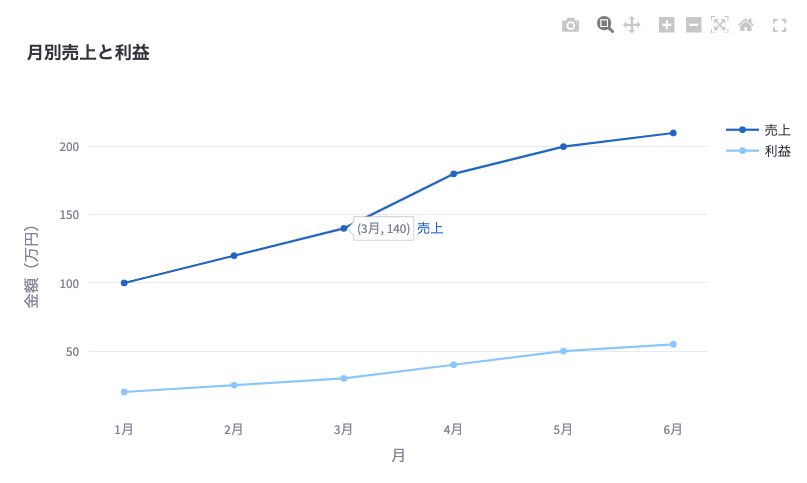
3. 基本的な折れ線グラフの作成
plotlyを使用して基本的な折れ線グラフを作成します。
# 基本的な折れ線グラフの作成
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['月'], y=df['売上'], mode='lines+markers', name='売上'))
fig.add_trace(go.Scatter(x=df['月'], y=df['利益'], mode='lines+markers', name='利益'))
fig.update_layout(title='月別売上と利益',
xaxis_title='月',
yaxis_title='金額(万円)')
st.plotly_chart(fig)コードの説明:
fig = go.Figure(): 新しいグラフ(Figure)オブジェクトを作成します。これは白紙のキャンバスのようなものです。fig.add_trace(): グラフに線を追加します。これを2回行って、売上と利益の2本の線を追加しています。go.Scatter(): 散布図や折れ線グラフを作成するための関数です。x=df['月']: x軸のデータとして、データフレームの’月’列を使用します。y=df['売上']またはy=df['利益']: y軸のデータとして、’売上’列や’利益’列を使用します。mode='lines+markers': 線とマーカー(点)の両方を表示するモードを指定します。name='売上'またはname='利益': 凡例に表示される名前を指定します。
fig.update_layout(): グラフ全体のレイアウトを設定します。title=: グラフのタイトルを設定します。xaxis_title=: x軸のタイトルを設定します。yaxis_title=: y軸のタイトルを設定します。
st.plotly_chart(fig): 作成したグラフをStreamlitアプリ上に表示します。
アプリ画面
4. グラフのカスタマイズ
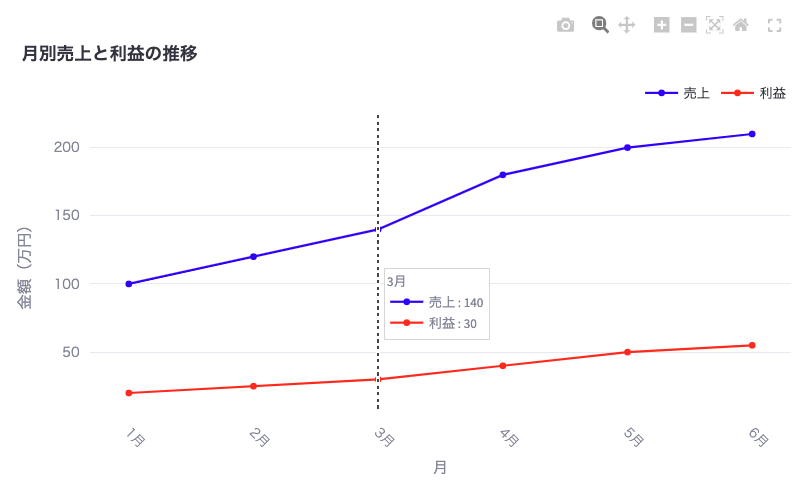
データ分析でよく使うカスタマイズオプションを追加します。
# カスタマイズされた折れ線グラフの作成
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['月'], y=df['売上'], mode='lines+markers', name='売上', line=dict(color='blue', width=2)))
fig.add_trace(go.Scatter(x=df['月'], y=df['利益'], mode='lines+markers', name='利益', line=dict(color='red', width=2)))
fig.update_layout(
title='月別売上と利益の推移',
xaxis_title='月',
yaxis_title='金額(万円)',
font=dict(family="Meiryo", size=12),
legend=dict(orientation="h", yanchor="bottom", y=1.02, xanchor="right", x=1),
hovermode="x unified"
)
fig.update_xaxes(tickangle=45)
fig.update_yaxes(zeroline=True, zerolinewidth=2, zerolinecolor='lightgrey')
st.plotly_chart(fig)このカスタマイズでは以下の点を改善しています。これらの設定により、グラフがより見やすく、情報が伝わりやすくなります。
line=dict(color='blue', width=2): 線の色と太さを指定します。font=dict(family="Meiryo", size=12): フォントの種類とサイズを設定します。legend=dict(...): 凡例の位置と形式を設定します。hovermode="x unified": マウスオーバー時の表示方法を設定します。fig.update_xaxes(tickangle=45): x軸のラベルを45度回転させます。fig.update_yaxes(...): y軸のゼロラインを追加します。
アプリ画面
5. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Add line chart using plotly」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step6:棒グラフ(plotly,go)の作成
1. 必要なモジュールの確認
このレッスンでは新しいモジュールは必要ありませんが、念のためapp.pyファイルの先頭にある現在のインポート文を確認します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go2. データの準備
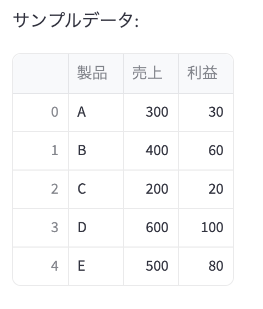
棒グラフ用のサンプルデータを作成します。
st.header('レッスン6: 棒グラフ(plotly,go)の作成')
# サンプルデータの作成
data = {
'製品': ['A', 'B', 'C', 'D', 'E'],
'売上': [300, 400, 200, 600, 500],
'利益': [30, 60, 20, 100, 80]
}
df = pd.DataFrame(data)
st.write('サンプルデータ:')
st.dataframe(df)アプリ画面
3. 基本的な棒グラフの作成
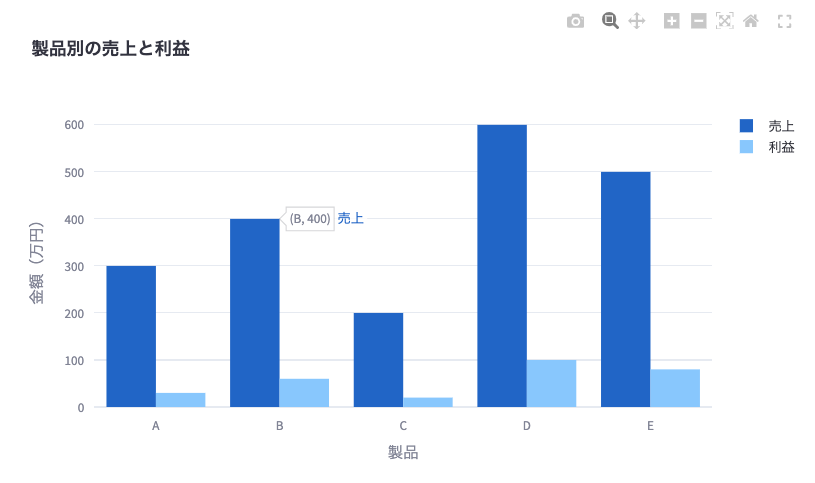
plotlyを使用して基本的な棒グラフを作成します。
# 基本的な棒グラフの作成
fig = go.Figure()
fig.add_trace(go.Bar(x=df['製品'], y=df['売上'], name='売上'))
fig.add_trace(go.Bar(x=df['製品'], y=df['利益'], name='利益'))
fig.update_layout(title='製品別の売上と利益',
xaxis_title='製品',
yaxis_title='金額(万円)',
barmode='group')
st.plotly_chart(fig)コードの説明:
fig = go.Figure(): 新しいグラフ(Figure)オブジェクトを作成します。これは白紙のキャンバスのようなものです。fig.add_trace(): グラフに棒を追加します。これを2回行って、売上と利益の2種類の棒を追加しています。go.Bar(): 棒グラフを作成するための関数です。x=df['製品']: x軸のデータとして、データフレームの’製品’列を使用します。y=df['売上']またはy=df['利益']: y軸のデータとして、’売上’列や’利益’列を使用します。name='売上'またはname='利益': 凡例に表示される名前を指定します。
fig.update_layout(): グラフ全体のレイアウトを設定します。title=: グラフのタイトルを設定します。xaxis_title=: x軸のタイトルを設定します。yaxis_title=: y軸のタイトルを設定します。barmode='group': 棒をグループ化して並べて表示するモードを指定します。
st.plotly_chart(fig): 作成したグラフをStreamlitアプリ上に表示します。
アプリ画面
4. グラフのカスタマイズ
データ分析でよく使うカスタマイズオプションを追加します。
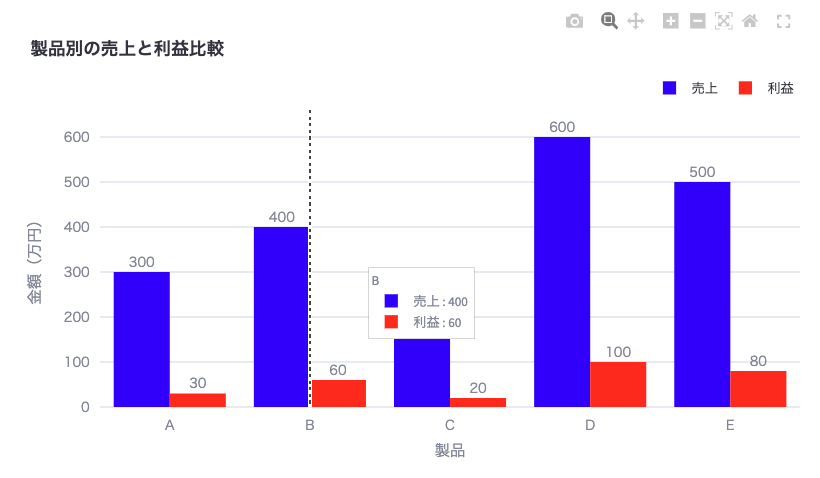
# カスタマイズされた棒グラフの作成
fig = go.Figure()
fig.add_trace(go.Bar(x=df['製品'], y=df['売上'], name='売上', marker_color='blue'))
fig.add_trace(go.Bar(x=df['製品'], y=df['利益'], name='利益', marker_color='red'))
fig.update_layout(
title='製品別の売上と利益比較',
xaxis_title='製品',
yaxis_title='金額(万円)',
barmode='group',
font=dict(family="Meiryo", size=12),
legend=dict(orientation="h", yanchor="bottom", y=1.02, xanchor="right", x=1),
hovermode="x unified"
)
fig.update_traces(texttemplate='%{y}', textposition='outside')
fig.update_yaxes(range=[0, max(df['売上'].max(), df['利益'].max()) * 1.1])
st.plotly_chart(fig)このカスタマイズでは以下の点を改善しています:
marker_color='blue'または'red': 棒の色を指定します。font=dict(family="Meiryo", size=12): フォントの種類とサイズを設定します。legend=dict(...): 凡例の位置と形式を設定します。hovermode="x unified": マウスオーバー時の表示方法を設定します。fig.update_traces(texttemplate='%{y}', textposition='outside'): 各棒の上に値を表示します。fig.update_yaxes(range=[...]): y軸の範囲を自動調整して、すべての値が見えるようにします。
これらの設定により、グラフがより見やすく、情報が伝わりやすくなります。例えば、各製品の売上と利益を一目で比較でき、具体的な数値も棒の上に表示されるため、詳細な情報も得られます。
アプリ画面
5. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Add bar chart using plotly」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step7:円グラフ(plotly,go)の作成
1. 必要なモジュールの確認
このレッスンでは新しいモジュールは必要ありませんが、念のためapp.pyファイルの先頭にある現在のインポート文を確認します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go2. データの準備
円グラフ用のサンプルデータを作成します。
st.header('レッスン7: 円グラフ(plotly,go)の作成')
# サンプルデータの作成
data = {
'商品': ['A', 'B', 'C', 'D', 'E'],
'売上': [300, 200, 180, 150, 120]
}
df = pd.DataFrame(data)
st.write('サンプルデータ:')
st.dataframe(df)アプリ画面
3. 基本的な円グラフの作成
plotlyを使用して基本的な円グラフを作成します。
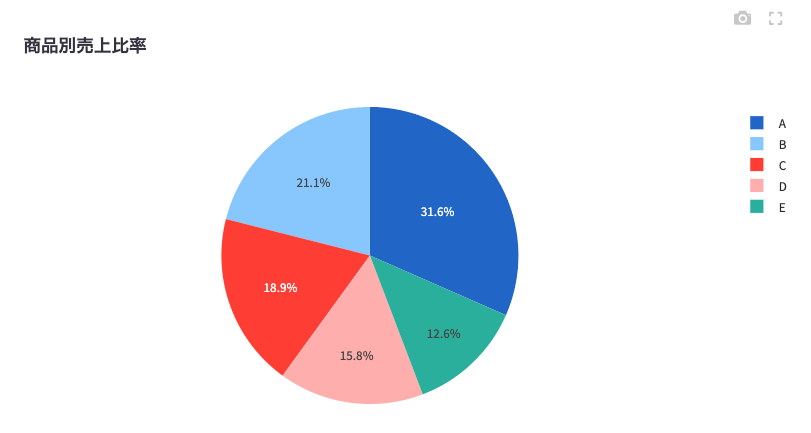
# 基本的な円グラフの作成
fig = go.Figure(data=[go.Pie(labels=df['商品'], values=df['売上'])])
fig.update_layout(title='商品別売上比率')
st.plotly_chart(fig)コードの説明:
fig = go.Figure(...): 新しいグラフ(Figure)オブジェクトを作成します。go.Pie(...): 円グラフを作成するための関数です。labels=df['商品']: 各セグメントのラベルとして、データフレームの’商品’列を使用します。values=df['売上']: 各セグメントの大きさとして、’売上’列を使用します。
fig.update_layout(title='商品別売上比率'): グラフのタイトルを設定します。st.plotly_chart(fig): 作成したグラフをStreamlitアプリ上に表示します。
アプリ画面
4. グラフのカスタマイズ
データ分析でよく使うカスタマイズオプションを追加します。
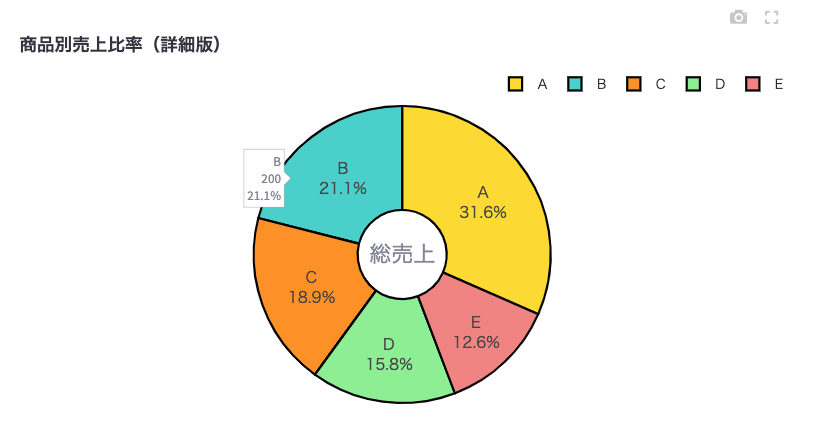
# カスタマイズされた円グラフの作成
colors = ['gold', 'mediumturquoise', 'darkorange', 'lightgreen', 'lightcoral']
fig = go.Figure(data=[go.Pie(labels=df['商品'],
values=df['売上'],
hole=.3,
marker=dict(colors=colors,
line=dict(color='#000000', width=2)))])
fig.update_traces(textposition='inside',
textinfo='percent+label',
hoverinfo='label+value+percent',
textfont_size=14)
fig.update_layout(
title='商品別売上比率(詳細版)',
font=dict(family="Meiryo", size=12),
legend=dict(orientation="h", yanchor="bottom", y=1.02, xanchor="right", x=1),
annotations=[dict(text='総売上', x=0.5, y=0.5, font_size=20, showarrow=False)]
)
st.plotly_chart(fig)コードの説明:
colors = [...]: 各セグメントに使用する色のリストを定義します。go.Pie(...): カスタマイズされた円グラフを作成します。hole=.3: グラフの中心に穴を開けて、ドーナツチャートにします。marker=dict(...): セグメントの色や境界線を設定します。
fig.update_traces(...): グラフの各セグメントの表示設定を行います。textposition='inside': テキストをセグメント内に配置します。textinfo='percent+label': 各セグメントに割合とラベルを表示します。hoverinfo='label+value+percent': マウスオーバー時に表示する情報を設定します。
fig.update_layout(...): グラフ全体のレイアウトを設定します。font=dict(...): フォントの種類とサイズを設定します。legend=dict(...): 凡例の位置を設定します。annotations=[...]: グラフの中心にテキストを追加します。
これらの設定により、グラフがより見やすく、情報量が豊富になります。例えば、各商品の売上比率が一目で分かり、具体的な数値もマウスオーバーで確認できます。
アプリ画面
5. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Add pie chart using plotly」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step8:キャッシュを使用したパフォーマンス最適化
キャッシュとは
キャッシュとは、一度計算した結果や取得したデータを一時的に保存し、再利用することで処理時間を短縮する技術です。例えば、大量のデータを読み込む処理や複雑な計算を行う関数があった場合、その結果をキャッシュしておくことで、2回目以降の呼び出しを高速化できます。
データ分析において、キャッシュは以下のような場面で特に有用です:
- 大規模なデータセットの読み込み
- 時間のかかる前処理や特徴量エンジニアリング
- 複雑な統計計算やモデルの学習結果
1. 必要なモジュールの確認と追加
app.pyファイルの先頭に以下のインポート文を追加または確認します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go
import numpy as np
import time2. キャッシュの基本と効果の確認
Streamlitのキャッシュ機能を使用して、時間のかかる処理の結果をメモリに保存し、再利用することができます。以下の例で、キャッシュの効果を確認します。
st.header('レッスン8: キャッシュを使用したパフォーマンス最適化')
def generate_large_dataset():
# 大きなデータセットを生成(約10秒かかる)
data = pd.DataFrame(np.random.randn(1000000, 5), columns=['A', 'B', 'C', 'D', 'E'])
return data
@st.cache_data
def load_data_cached():
return generate_large_dataset()
def load_data_uncached():
return generate_large_dataset()
st.subheader("キャッシュなしの場合")
start_time = time.time()
data_uncached = load_data_uncached()
end_time = time.time()
st.write(f"データ読み込み時間: {end_time - start_time:.2f} 秒")
st.write(data_uncached.head())
st.subheader("キャッシュありの場合")
start_time = time.time()
data_cached = load_data_cached()
end_time = time.time()
st.write(f"データ読み込み時間: {end_time - start_time:.2f} 秒")
st.write(data_cached.head())
st.write("キャッシュありの場合、2回目以降の読み込みは非常に高速になります。")コードの説明:
generate_large_dataset(): 大きなデータフレームを生成する関数です。実際のデータ分析では、大規模なCSVファイルの読み込みや、APIからのデータ取得などが該当します。@st.cache_data: この装飾子(デコレータ)をつけることで、関数の結果がキャッシュされます。load_data_cached(): キャッシュを使用してデータを読み込む関数です。load_data_uncached(): キャッシュを使用せずにデータを読み込む関数です。
リロードした際のキャッシュ有無の読み込み時間比較
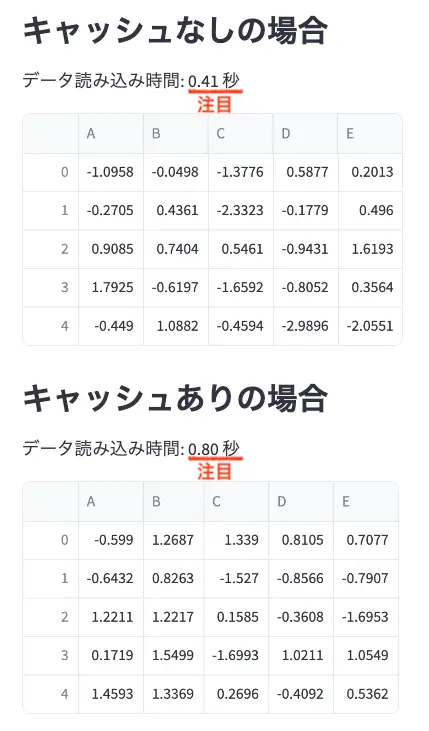

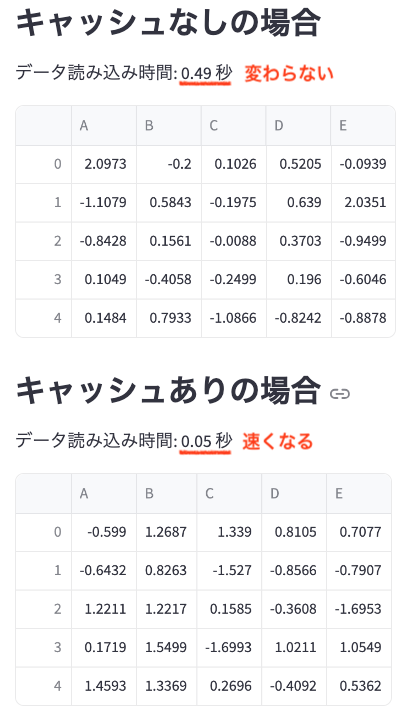
データ分析での使用例:
- 日次の売上データなど、頻繁に更新されないデータセットの読み込み
- 機械学習モデルの学習結果の保存と再利用
3. 大規模データセットの処理
大規模なデータセットを扱う場合、st.cache_dataの代わりにst.cache_resourceを使用することで、メモリ使用量を最適化できます。
@st.cache_resource
def load_large_dataset():
return pd.DataFrame(
np.random.randn(1000000, 5),
columns=['A', 'B', 'C', 'D', 'E']
)
st.subheader("大規模データセットの処理")
start_time = time.time()
large_data = load_large_dataset()
end_time = time.time()
st.write(f"大規模データセット読み込み時間: {end_time - start_time:.2f} 秒")
st.write(f"データセットの形状: {large_data.shape}")
st.write(large_data.head())コードの説明:
@st.cache_resource: この装飾子は、st.cache_dataよりもメモリ効率が良く、大規模なデータセットやモデルに適しています。load_large_dataset(): 大規模なデータセットを生成し、キャッシュする関数です。
st.cache_dataとst.cache_resourceの大規模データセットの処理比較
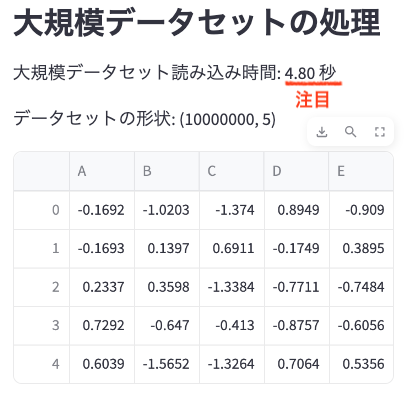
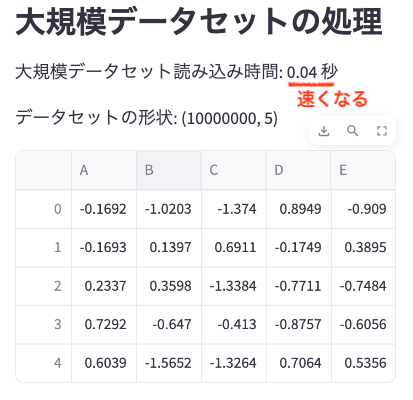
データ分析での使用例:
- ビッグデータの分析(例:数百万行の顧客データ)
- 大規模な機械学習モデル(例:ディープラーニングモデル)の保存と再利用
4. キャッシュの無効化
データが更新された場合など、キャッシュを無効化したい場合があります。
@st.cache_data(ttl=10)
def get_current_time():
return pd.Timestamp.now()
st.subheader("キャッシュの無効化")
st.write("現在時刻(10秒ごとに更新):")
st.write(get_current_time())コードの説明:
@st.cache_data(ttl=10): この装飾子は、キャッシュの有効期限を10秒に設定します。get_current_time(): 現在時刻を返す関数です。10秒ごとに更新されます。
アプリ画面

データ分析での使用例:
- リアルタイムのセンサーデータの表示(例:10秒ごとに更新される温度データ)
- 株価データなど、頻繁に更新される金融データの表示
5. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Add improved caching examples for performance optimization」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step9:セッション状態の管理
1. 必要なモジュールの確認
app.pyファイルの先頭に以下のインポート文を追加または確認します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go
import numpy as np
import time新しいモジュールは必要ありませんが、既存のものを使用します。
2. セッション状態の基本
セッション状態を使用して、カウンターを実装します。
注意:このステップでは st.button を使用しますが、その詳細な説明は次のステップで行います。
st.header('レッスン9: セッション状態の管理')
if 'count' not in st.session_state:
st.session_state.count = 0
st.write(f"現在のカウント: {st.session_state.count}")
if st.button('カウントアップ'):
st.session_state.count += 1
st.rerun()コードの説明:
if 'count' not in st.session_state:: セッション状態に’count’が存在しない場合の条件分岐です。st.session_state.count = 0: セッション状態に’count’という変数を作成し、0で初期化します。st.write(f"現在のカウント: {st.session_state.count}"): 現在のカウント値を表示します。if st.button('カウントアップ'):: ボタンがクリックされたときの条件分岐です。st.session_state.count += 1: カウント値を1増やします。st.rerun(): アプリケーションを再実行し、更新された値を表示します。
アプリ画面
データ分析での使用例:
- データフィルタリングの状態保持:ユーザーが選択したフィルター条件を保存し、分析セッション中に維持します。
- 分析ステップの進捗管理:多段階の分析プロセスにおいて、現在のステップを記録し、ユーザーが中断して後で再開できるようにします。
3. フォーム入力の保持
セッション状態を使用して、フォーム入力を保持する例を示します。
if 'user_name' not in st.session_state:
st.session_state.user_name = ""
if 'user_email' not in st.session_state:
st.session_state.user_email = ""
user_name = st.text_input("ユーザー名", value=st.session_state.user_name)
user_email = st.text_input("メールアドレス", value=st.session_state.user_email)
if st.button("ユーザー情報を保存"):
st.session_state.user_name = user_name
st.session_state.user_email = user_email
st.success("ユーザー情報が保存されました!")
st.write(f"セッションに保存されたユーザー名: {st.session_state.user_name}")
st.write(f"セッションに保存されたメールアドレス: {st.session_state.user_email}")コードの説明:
if 'user_name' not in st.session_state:: ユーザー名がセッション状態に存在しない場合の条件分岐です。st.session_state.user_name = "": ユーザー名を空文字列で初期化します。user_name = st.text_input("ユーザー名", value=st.session_state.user_name): テキスト入力フィールドを作成し、初期値としてセッション状態の値を使用します。if st.button("ユーザー情報を保存"):: 保存ボタンがクリックされたときの条件分岐です。st.session_state.user_name = user_name: 入力されたユーザー名をセッション状態に保存します。st.success("ユーザー情報が保存されました!"): 成功メッセージを表示します。
アプリ画面

データ分析での使用例:
- ユーザープロファイル管理:データ分析ツールにおいて、ユーザーの設定や好みを保存し、セッション中に維持します。
- 分析パラメータの保存:複雑な分析モデルのパラメータをユーザーが入力し、セッション中にそれらを保持します。
4. データフレームの状態管理
セッション状態を使用して、データフレームの状態を管理する例を示します。
if 'df' not in st.session_state:
st.session_state.df = pd.DataFrame(columns=['商品', '価格'])
product = st.text_input("商品名を入力")
price = st.number_input("価格を入力", min_value=0)
if st.button("商品データを追加"):
new_data = pd.DataFrame({'商品': [product], '価格': [price]})
st.session_state.df = pd.concat([st.session_state.df, new_data], ignore_index=True)
st.write("現在の商品データ:")
st.write(st.session_state.df)
if st.button("データをリセット"):
st.session_state.df = pd.DataFrame(columns=['商品', '価格'])
st.rerun()コードの説明:
if 'df' not in st.session_state:: データフレームがセッション状態に存在しない場合の条件分岐です。st.session_state.df = pd.DataFrame(columns=['商品', '価格']): 空のデータフレームを初期化します。product = st.text_input("商品名を入力"): 商品名の入力フィールドを作成します。if st.button("商品データを追加"):: データ追加ボタンがクリックされたときの条件分岐です。new_data = pd.DataFrame({'商品': [product], '価格': [price]}): 新しいデータ行を作成します。st.session_state.df = pd.concat([st.session_state.df, new_data], ignore_index=True): 新しいデータを既存のデータフレームに追加します。if st.button("データをリセット"):: リセットボタンがクリックされたときの条件分岐です。
アプリ画面
データ分析での使用例:
- インタラクティブなデータ収集:ユーザーが段階的にデータを入力し、それをリアルタイムで分析に使用する場合。
- データクリーニングプロセス:ユーザーがデータを確認し、必要に応じて編集や削除を行う際に、変更をセッション中に保持します。
5. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Update session state management examples」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。

本コンテンツへの意見や質問