
Step10:ボタンとチェックボックス
1. 必要なモジュールの確認
app.pyファイルの先頭に以下のインポート文を確認します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go
import numpy as np
import time2. ボタンの基本
st.header('レッスン10: ボタンとチェックボックス')
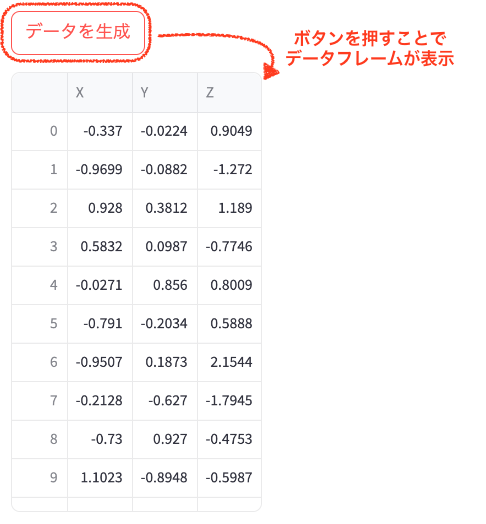
if st.button('データを生成', key='generate_data'):
random_data = pd.DataFrame(np.random.randn(20, 3), columns=['X', 'Y', 'Z'])
st.write(random_data)コードの説明:
st.button('データを生成', key='generate_data'): 「データを生成」というラベルのボタンを作成します。keyパラメータは、このボタンを一意に識別するために使用します。if文: ボタンが押されたときに実行される条件文です。pd.DataFrame(np.random.randn(20, 3), columns=['X', 'Y', 'Z']): 20行3列のランダムなデータを持つデータフレームを作成します。st.write(random_data): 生成されたデータフレームを画面に表示します。
アプリ画面
3. チェックボックスの基本
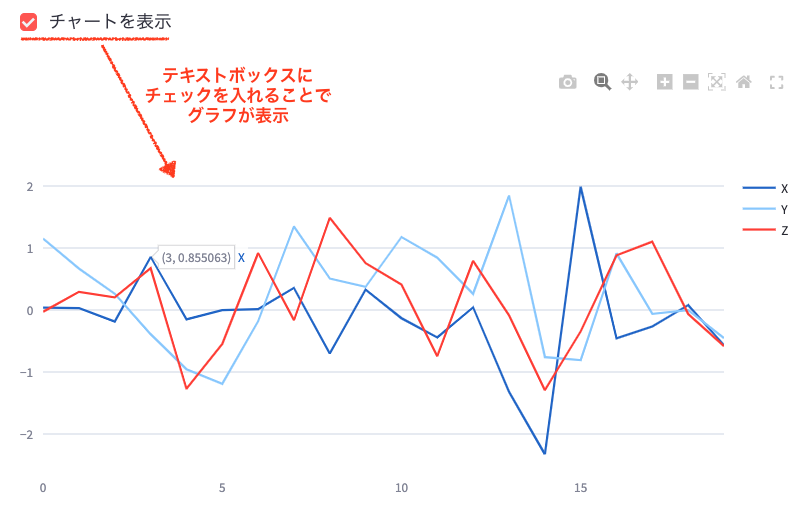
show_chart = st.checkbox('チャートを表示', key='show_chart')
if show_chart:
chart_data = pd.DataFrame(np.random.randn(20, 3), columns=['X', 'Y', 'Z'])
fig = go.Figure()
for column in chart_data.columns:
fig.add_trace(go.Scatter(x=chart_data.index, y=chart_data[column], mode='lines', name=column))
st.plotly_chart(fig)コードの説明:
st.checkbox('チャートを表示', key='show_chart'): 「チャートを表示」というラベルのチェックボックスを作成します。if show_chart:: チェックボックスがチェックされている場合に実行される条件文です。pd.DataFrame(np.random.randn(20, 3), columns=['X', 'Y', 'Z']): ランダムなデータを生成します。fig = go.Figure(): 新しいグラフオブジェクトを作成します。forループ: 各列のデータを使って折れ線グラフを作成します。st.plotly_chart(fig): 作成したグラフを表示します。
アプリ画面
4. ボタンを使った複数の操作
if 'counter' not in st.session_state:
st.session_state.counter = 0
col1, col2, col3 = st.columns(3)
if col1.button('カウントアップ', key='count_up'):
st.session_state.counter += 1
if col2.button('カウントダウン', key='count_down'):
st.session_state.counter -= 1
if col3.button('リセット', key='reset_count'):
st.session_state.counter = 0
st.write(f"現在のカウント: {st.session_state.counter}")コードの説明:
st.session_state.counter: カウンターの値を保存するセッション状態変数です。st.columns(3): 画面を3つの列に分割します。- 各列にボタンを配置し、それぞれ異なる操作(カウントアップ、カウントダウン、リセット)を行います。
st.write(f"現在のカウント: {st.session_state.counter}"): 現在のカウント値を表示します。
アプリ画面

5. チェックボックスを使った条件付き表示
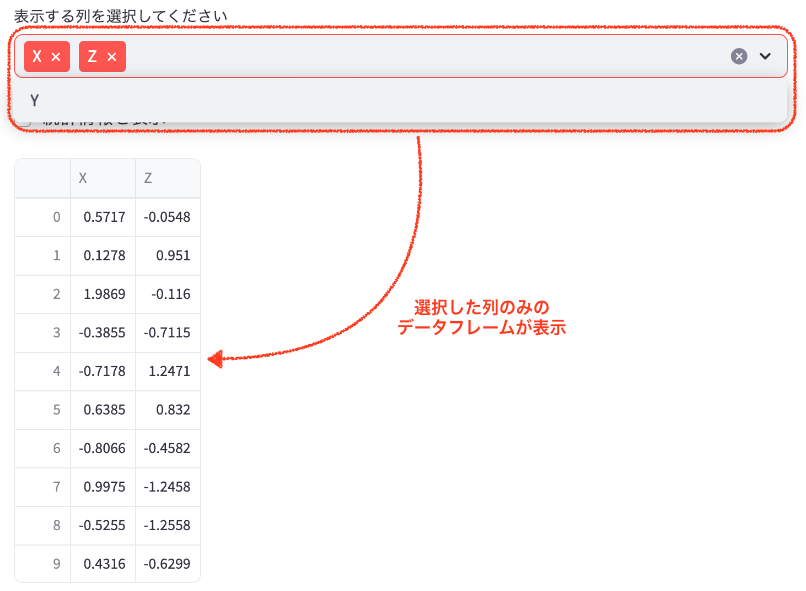
column_options = st.multiselect(
'表示する列を選択してください',
['X', 'Y', 'Z'],
['X', 'Y', 'Z'],
key='column_selection')
sample_data = pd.DataFrame(np.random.randn(10, 3), columns=['X', 'Y', 'Z'])
st.write(sample_data[column_options])
コードの説明:
st.multiselect(): 複数の選択肢から項目を選べるドロップダウンメニューを作成します。sample_data = pd.DataFrame(...): サンプルデータを生成します。st.write(sample_data[column_options]): 選択された列のみのデータを表示します。
アプリ画面
6. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Update button and checkbox examples with unique keys」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step11:スライダーとセレクトボックス
1. 必要なモジュールの確認
app.pyファイルの先頭に以下のインポート文を確認します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go
import numpy as np
import time2. スライダーの基本
st.header('レッスン11: スライダーとセレクトボックス')
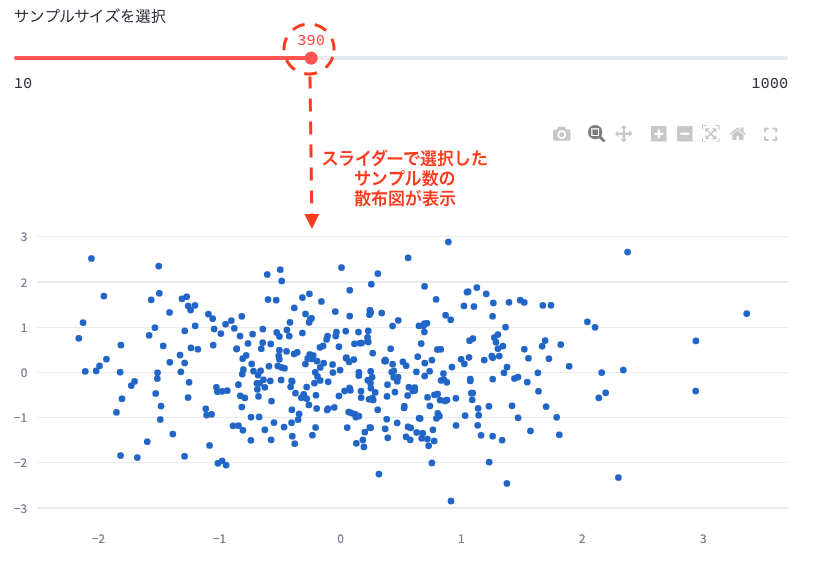
sample_size = st.slider('サンプルサイズを選択', min_value=10, max_value=1000, value=100, step=10, key='sample_slider')
data_sample1 = pd.DataFrame(np.random.randn(sample_size, 2), columns=['X', 'Y'])
fig1 = go.Figure()
fig1.add_trace(go.Scatter(x=data_sample1['X'], y=data_sample1['Y'], mode='markers'))
st.plotly_chart(fig1)コードの説明:
st.slider(): スライダーを作成します。ユーザーが値を連続的に選択できます。'サンプルサイズを選択': スライダーのラベルmin_value=10, max_value=1000: スライダーの最小値と最大値value=100: スライダーの初期値step=10: スライダーの増減単位key='sample_slider': このスライダーの一意の識別子
pd.DataFrame(np.random.randn(sample_size, 2), columns=['X', 'Y']): 選択されたサンプルサイズに基づいてランダムなデータを生成します。go.Figure(): 新しいグラフオブジェクトを作成します。fig1.add_trace(): グラフにデータを追加します。ここでは散布図を作成しています。st.plotly_chart(fig1): 作成したグラフを表示します。
アプリ画面
3. 範囲スライダー
data_sample2 = pd.DataFrame(np.random.uniform(0, 100, size=(1000, 2)), columns=['P', 'Q'])
range_values = st.slider('値の範囲を選択', min_value=0.0, max_value=100.0, value=(25.0, 75.0), key='range_slider')
filtered_data = data_sample2[(data_sample2['P'] >= range_values[0]) & (data_sample2['P'] <= range_values[1])]
fig2 = go.Figure()
fig2.add_trace(go.Scatter(x=filtered_data['P'], y=filtered_data['Q'], mode='markers'))
st.plotly_chart(fig2)コードの説明:
st.slider(): ここでは範囲スライダーを作成します。2つの値を同時に選択できます。value=(25.0, 75.0): スライダーの初期範囲を設定します。
filtered_data = ...: 選択された範囲に基づいてデータをフィルタリングします。
アプリ画面

4. セレクトボックス
data_sample3 = pd.DataFrame(np.random.randn(200, 2), columns=['M', 'N'])
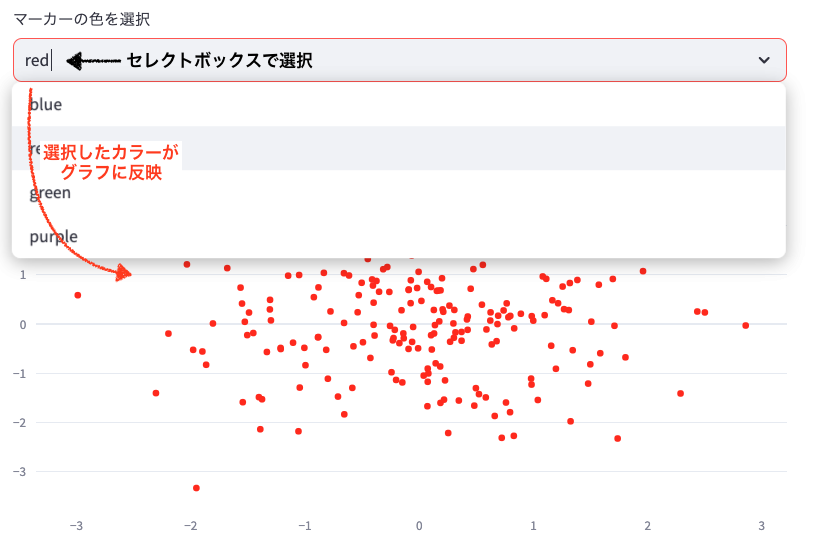
color_option = st.selectbox('マーカーの色を選択', ['blue', 'red', 'green', 'purple'], key='color_select')
fig3 = go.Figure()
fig3.add_trace(go.Scatter(x=data_sample3['M'], y=data_sample3['N'], mode='markers', marker=dict(color=color_option)))
st.plotly_chart(fig3)コードの説明:
st.selectbox(): ドロップダウンメニューを作成します。ユーザーが事前定義された選択肢から1つを選べます。['blue', 'red', 'green', 'purple']: 選択可能な色のリスト
marker=dict(color=color_option): 選択された色でマーカーの色を設定します。
アプリ画面
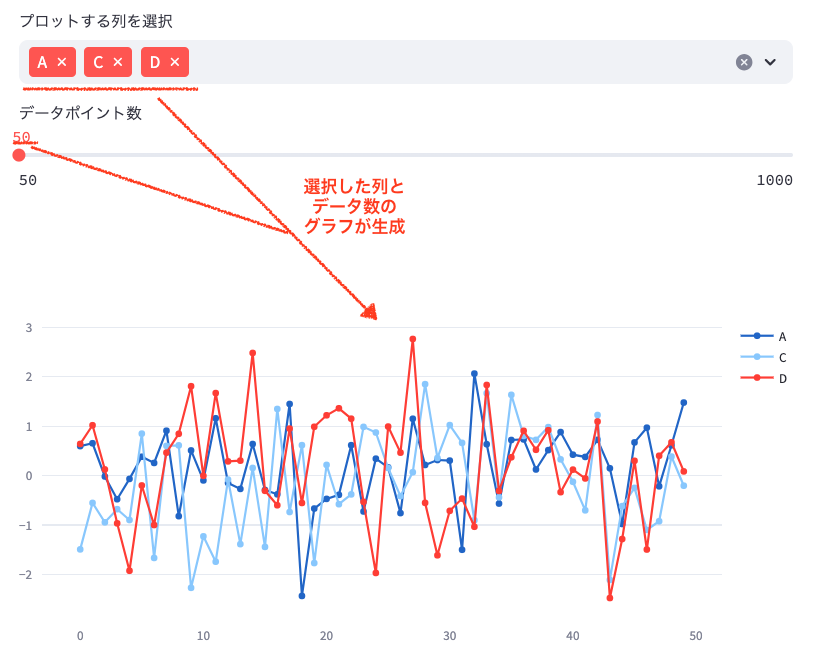
5. マルチセレクトとスライダーの組み合わせ
columns_to_plot = st.multiselect('プロットする列を選択', ['A', 'B', 'C', 'D'], default=['A', 'B'], key='column_multiselect')
num_points = st.slider('データポイント数', min_value=50, max_value=1000, value=200, step=50, key='points_slider')
data_sample4 = pd.DataFrame(np.random.randn(num_points, 4), columns=['A', 'B', 'C', 'D'])
fig4 = go.Figure()
for col in columns_to_plot:
fig4.add_trace(go.Scatter(x=data_sample4.index, y=data_sample4[col], mode='lines+markers', name=col))
st.plotly_chart(fig4)コードの説明:
st.multiselect(): 複数の選択肢を同時に選べるドロップダウンメニューを作成します。default=['A', 'B']: デフォルトで選択される値
for col in columns_to_plot:: 選択された各列に対してグラフを作成します。fig4.add_trace(): 選択された各列のデータをグラフに追加します。
アプリ画面
6. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Update slider and selectbox examples with independent datasets」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step12:ファイルアップローダー
1. 必要なモジュールの確認と追加
app.pyファイルの先頭に以下のインポート文を追加または確認します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go
import numpy as np
import time
import io
import openpyxlrequirements.txtファイルに以下の行を追加し、必要なパッケージをインストールしてください:
openpyxl==3.1.2ターミナルで以下のコマンドを実行してパッケージをインストールします:
pip install -r requirements.txt2. サンプルデータのダウンロードと保存
このレッスンで使用するサンプルデータを下記からダウンロードし、app.pyと同じディレクトリにdataというフォルダを作成して保存してください:
VSCode画面
3. CSVファイルのアップロードと表示
st.header('レッスン12: ファイルアップローダー')
uploaded_csv = st.file_uploader("CSVファイルをアップロードしてください", type="csv", key="csv_uploader")
if uploaded_csv is not None:
df_csv = pd.read_csv(uploaded_csv)
st.write("アップロードされたCSVファイルの内容:")
st.write(df_csv)
st.write("データの基本統計:")
st.write(df_csv.describe())
# 数値列の選択
numeric_columns = df_csv.select_dtypes(include=[np.number]).columns.tolist()
selected_column = st.selectbox("グラフ化する列を選択してください", numeric_columns, key="csv_column_select")
# ヒストグラムの作成
fig = go.Figure(data=[go.Histogram(x=df_csv[selected_column])])
fig.update_layout(title=f"{selected_column}のヒストグラム")
st.plotly_chart(fig)コードの説明:
st.file_uploader(): ファイルをアップロードするための入力欄を作成します。"CSVファイルをアップロードしてください": ユーザーに表示されるメッセージです。type="csv": アップロードを許可するファイルの種類を指定します。key="csv_uploader": この要素の一意の識別子です。
if uploaded_csv is not None:: ファイルがアップロードされたかどうかを確認します。pd.read_csv(uploaded_csv): アップロードされたCSVファイルを読み込みます。st.write(df_csv): 読み込んだデータを画面に表示します。df_csv.select_dtypes(include=[np.number]): 数値型の列のみを選択します。st.selectbox(): ドロップダウンメニューを作成し、ユーザーに列を選択させます。go.Figure(data=[go.Histogram(...)]): 選択された列のヒストグラムを作成します。st.plotly_chart(fig): 作成したグラフを表示します。
アプリケーションの画面説明:
- 画面上部に「CSVファイルをアップロードしてください」というメッセージと、ファイルをアップロードするためのボタンが表示されています。
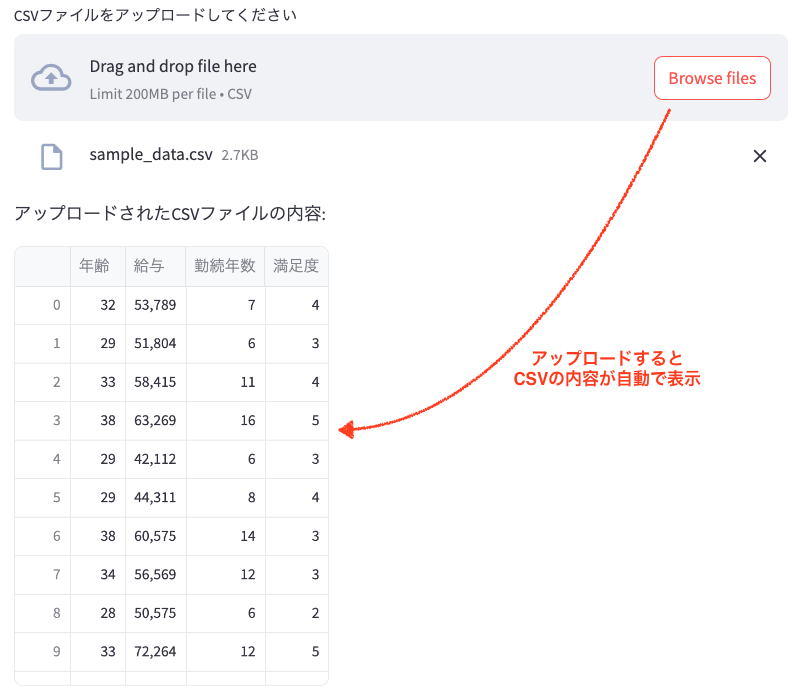
- CSVファイルをアップロードすると、自動的にファイルの内容が表形式で表示されます。
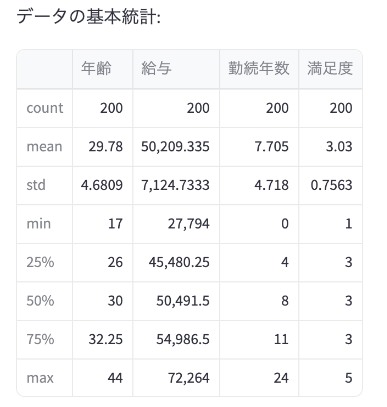
- その下に「データの基本統計」として、数値データの要約(平均、標準偏差など)が表示されます。
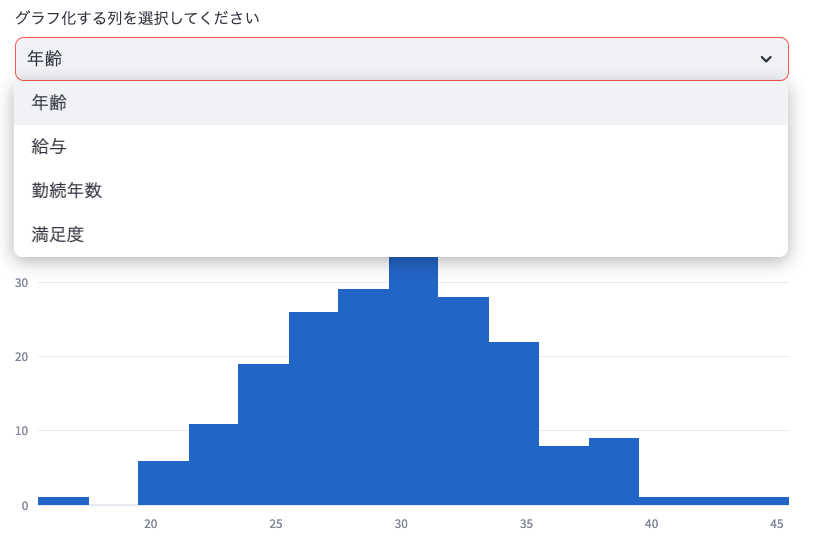
- 「グラフ化する列を選択してください」というドロップダウンメニューがあり、ここで選択した列のヒストグラムが自動的に生成されます。
- ヒストグラムは選択した列のデータ分布を視覚的に表現しています。

これらの機能により、ユーザーは簡単にCSVファイルのデータを閲覧し、基本的な分析を行うことができます。
4. Excelファイルのアップロードと表示
uploaded_excel = st.file_uploader("Excelファイルをアップロードしてください", type=["xlsx", "xls"], key="excel_uploader")
if uploaded_excel is not None:
excel_file = openpyxl.load_workbook(uploaded_excel)
sheet_names = excel_file.sheetnames
st.write("シート名:")
st.write(sheet_names)
selected_sheet = st.radio("分析するシートを選択してください", sheet_names, key="sheet_selector")
df_excel = pd.read_excel(uploaded_excel, sheet_name=selected_sheet)
st.write(f"選択されたシート '{selected_sheet}' の内容:")
st.write(df_excel)
# 列の選択
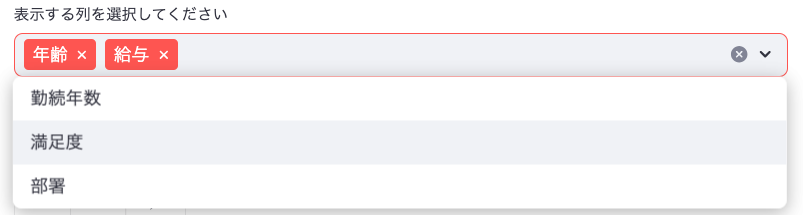
selected_columns = st.multiselect("表示する列を選択してください", df_excel.columns.tolist(), key="excel_column_select")
if selected_columns:
st.write("選択された列のデータ:")
st.write(df_excel[selected_columns])
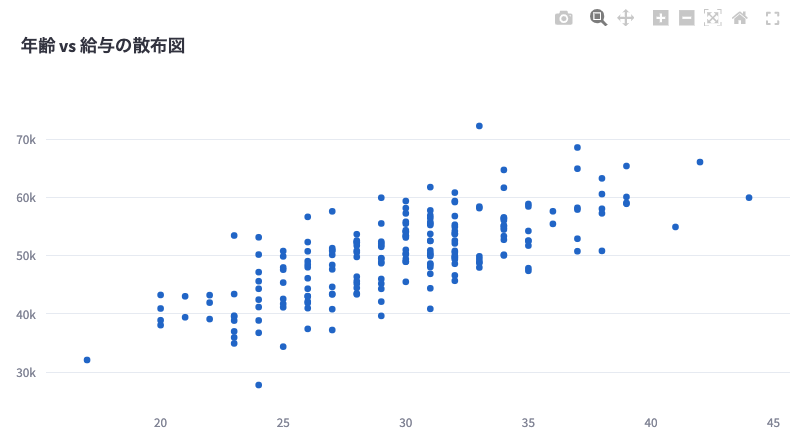
# 散布図の作成(2つの列が選択された場合)
if len(selected_columns) == 2:
fig = go.Figure(data=go.Scatter(x=df_excel[selected_columns[0]],
y=df_excel[selected_columns[1]],
mode='markers'))
fig.update_layout(title=f"{selected_columns[0]} vs {selected_columns[1]}の散布図")
st.plotly_chart(fig)コードの説明:
type=["xlsx", "xls"]: Excelファイルの拡張子を指定します。openpyxl.load_workbook(uploaded_excel): Excelファイルを読み込みます。excel_file.sheetnames: Excelファイル内のシート名のリストを取得します。st.radio(): ラジオボタンを作成し、ユーザーにシートを選択させます。pd.read_excel(): 選択されたシートのデータを読み込みます。st.multiselect(): 複数選択可能なドロップダウンメニューを作成します。df_excel[selected_columns]: 選択された列のデータのみを表示します。if len(selected_columns) == 2:: 2つの列が選択された場合、散布図を作成します。go.Figure(data=go.Scatter(...)): 散布図を作成します。st.plotly_chart(fig): 作成した散布図を表示します。
アプリケーションの画面説明:
- 画面上部に「Excelファイルをアップロードしてください」というメッセージと、ファイルをアップロードするためのボタンが表示されています。

- Excelファイルをアップロードすると、ファイル内のシート名が表示され、ラジオボタンでシートを選択できます。
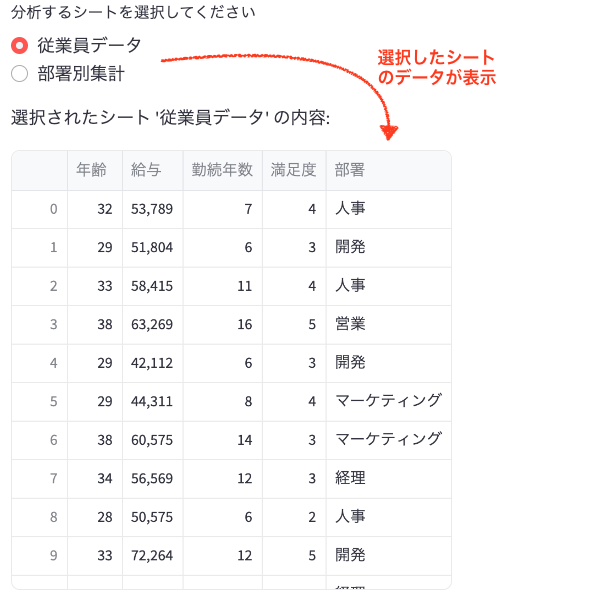
- シートを選択すると、そのシートの内容が表形式で自動的に表示されます。
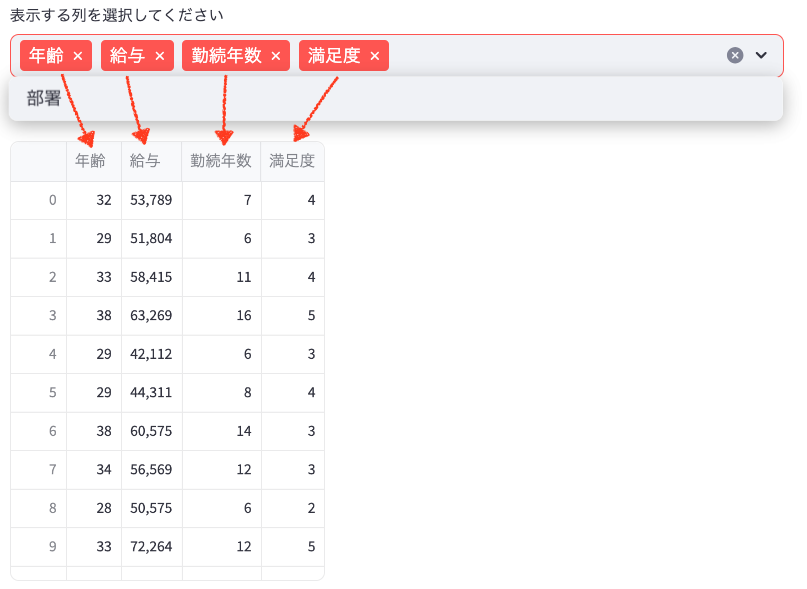
- 「表示する列を選択してください」という複数選択可能なドロップダウンメニューがあり、ここで選択した列のデータのみが表示されます。
- 2つの列を選択すると、自動的にそれらの列のデータを使用した散布図が生成されます。
これらの機能により、ユーザーはExcelファイルの特定のシートや列のデータを簡単に閲覧し、視覚化することができます。ファイルのアップロードから、データの表示、視覚化まで、すべての操作がこの1つの画面で完結します。
5. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Update file uploader with Excel sheet selection」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step13:カラムとコンテナによるレイアウト
1.必要なモジュールの確認
app.pyファイルの先頭に以下のインポート文を確認します:
import streamlit as st
import pandas as pd
import plotly.graph_objects as go
import numpy as np
import time
import io
import openpyxlこのレッスンでは新しいモジュールは必要ありません。
2. カラムレイアウトの基本
ここでは、画面を複数の列に分割し、各列に異なる要素を配置する方法を学びます。
st.header('レッスン13: カラムとコンテナによるレイアウト')
col1, col2, col3 = st.columns(3)
with col1:
st.subheader("列1")
st.write("ここは1列目です。")
st.button("ボタン1", key="button1")
with col2:
st.subheader("列2")
st.write("ここは2列目です。")
st.checkbox("チェックボックス", key="checkbox1")
with col3:
st.subheader("列3")
st.write("ここは3列目です。")
st.radio("ラジオボタン", ["選択肢1", "選択肢2", "選択肢3"], key="radio1")
説明:
st.columns(3): 画面を3つの列に分割します。with col1:,with col2:,with col3:: それぞれの列の中に要素を配置します。- 各列には異なる種類の要素(ボタン、チェックボックス、ラジオボタン)を配置しています。

3. 異なる幅のカラム
カラムの幅を調整して、より柔軟なレイアウトを作成する方法を示します。
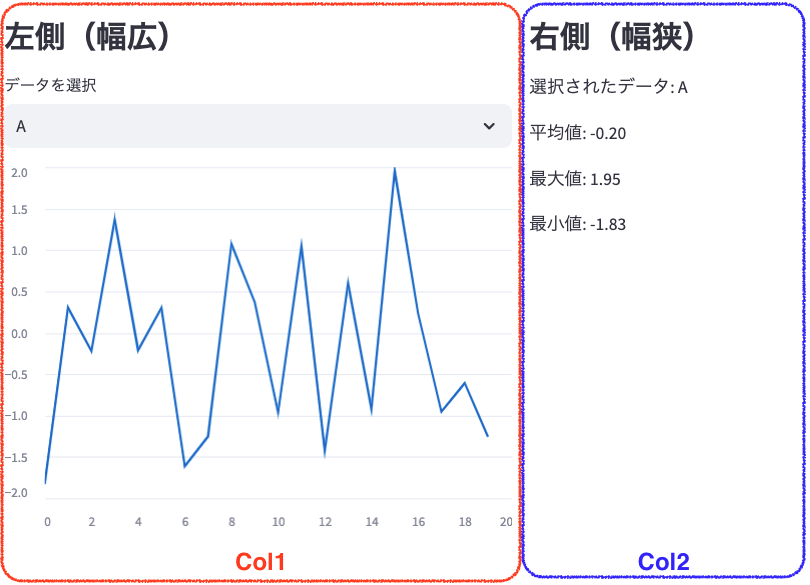
col_left, col_right = st.columns([2, 1])
with col_left:
st.subheader("左側(幅広)")
chart_data = pd.DataFrame(np.random.randn(20, 3), columns=["A", "B", "C"])
selected_column = st.selectbox("データを選択", ["A", "B", "C"], key="data_select")
st.line_chart(chart_data[selected_column])
with col_right:
st.subheader("右側(幅狭)")
st.write(f"選択されたデータ: {selected_column}")
st.write(f"平均値: {chart_data[selected_column].mean():.2f}")
st.write(f"最大値: {chart_data[selected_column].max():.2f}")
st.write(f"最小値: {chart_data[selected_column].min():.2f}")説明:
st.columns([2, 1]): 画面を2:1の比率で2列に分割します。- 左側の列にはグラフを、右側の列には選択されたデータの情報を表示しています。
st.selectbox(): ドロップダウンメニューを作成し、ユーザーにデータを選択させます。st.line_chart(): 選択されたデータの折れ線グラフを表示します。
4. コンテナの使用
関連する要素をグループ化してレイアウトを整理する方法を学びます。
with st.container():
st.subheader("データ分析セクション")
st.write("このコンテナ内にデータ分析関連の要素をグループ化します。")
data_container = st.container()
data = pd.DataFrame({
'名前': ['Alice', 'Bob', 'Charlie', 'David'],
'年齢': [25, 30, 35, 40],
'都市': ['東京', '大阪', '名古屋', '福岡']
})
data_container.dataframe(data)
analysis_type = st.radio("分析タイプ", ["平均年齢", "都市別人数"], key="analysis_type")
if analysis_type == "平均年齢":
data_container.write(f"平均年齢: {data['年齢'].mean():.1f}歳")
else:
data_container.write(data['都市'].value_counts())説明:
st.container(): 関連する要素をグループ化するためのコンテナを作成します。data_container.dataframe(data): コンテナ内にデータフレームを表示します。st.radio(): ラジオボタンを作成し、ユーザーに分析タイプを選択させます。- 選択された分析タイプに応じて、異なる結果をコンテナ内に表示します。

5. ネストされたレイアウト
カラムとコンテナを組み合わせて、より複雑なレイアウトを作成する方法を示します。
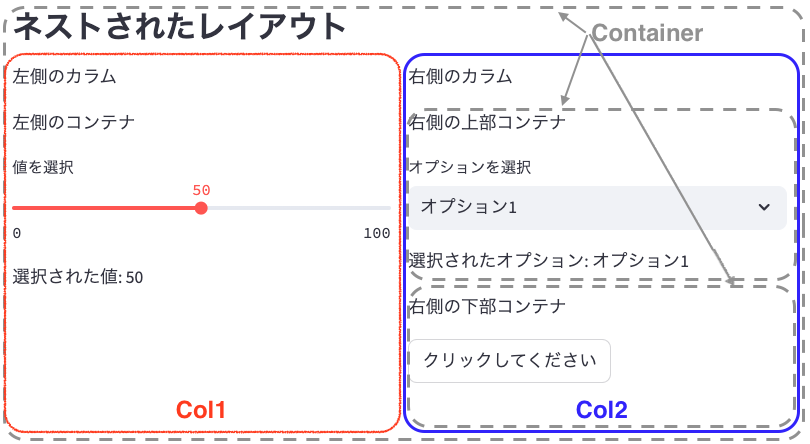
with st.container():
st.subheader("ネストされたレイアウト")
col1, col2 = st.columns(2)
with col1:
st.write("左側のカラム")
with st.container():
st.write("左側のコンテナ")
slider_value = st.slider("値を選択", 0, 100, 50, key="nested_slider")
st.write(f"選択された値: {slider_value}")
with col2:
st.write("右側のカラム")
with st.container():
st.write("右側の上部コンテナ")
option = st.selectbox("オプションを選択", ["オプション1", "オプション2", "オプション3"], key="nested_select")
st.write(f"選択されたオプション: {option}")
with st.container():
st.write("右側の下部コンテナ")
if st.button("クリックしてください", key="nested_button"):
st.write("ボタンがクリックされました!")説明:
- 最初に大きなコンテナを作成し、その中に2つの列を配置しています。
- 左側の列には1つのコンテナ、右側の列には2つのコンテナを配置しています。
- 各コンテナ内に異なる種類の入力要素(スライダー、セレクトボックス、ボタン)を配置しています。
6. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Add layout examples using columns and containers」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step14:エクスパンダーとサイドバーによるレイアウト
1. 必要なモジュールの確認
import streamlit as st
import pandas as pd
import plotly.graph_objects as go
import numpy as np
import time
import io
import openpyxl2. エクスパンダーの基本
エクスパンダーを使用して、コンテンツを折りたたみ可能なセクションに整理します。
st.header('レッスン14: エクスパンダーとサイドバーによるレイアウト')
st.subheader("エクスパンダーの使用例")
# 1年分のデータを生成
sales_data = pd.DataFrame({
'日付': pd.date_range(start='2023-01-01', end='2023-12-31'),
'売上': np.random.randint(1000, 5000, 365),
'商品': np.random.choice(['A', 'B', 'C'], 365)
})
with st.expander("データセットの詳細を表示"):
st.dataframe(sales_data)
with st.expander("グラフを表示"):
fig = go.Figure(data=go.Scatter(x=sales_data['日付'], y=sales_data['売上'], mode='lines+markers'))
fig.update_layout(title='日別売上推移')
st.plotly_chart(fig)
with st.expander("統計情報"):
st.write(f"総売上: {sales_data['売上'].sum():,}円")
st.write(f"平均売上: {sales_data['売上'].mean():.2f}円")
st.write(f"最高売上: {sales_data['売上'].max():,}円")
st.write(f"最低売上: {sales_data['売上'].min():,}円")説明:
st.expander(): クリックで展開・折りたたみができるセクションを作成します。with st.expander("タイトル"):: エクスパンダー内にコンテンツを配置します。- エクスパンダー内には、データフレームやグラフなど、様々な要素を配置できます。
アプリケーション画面の説明:
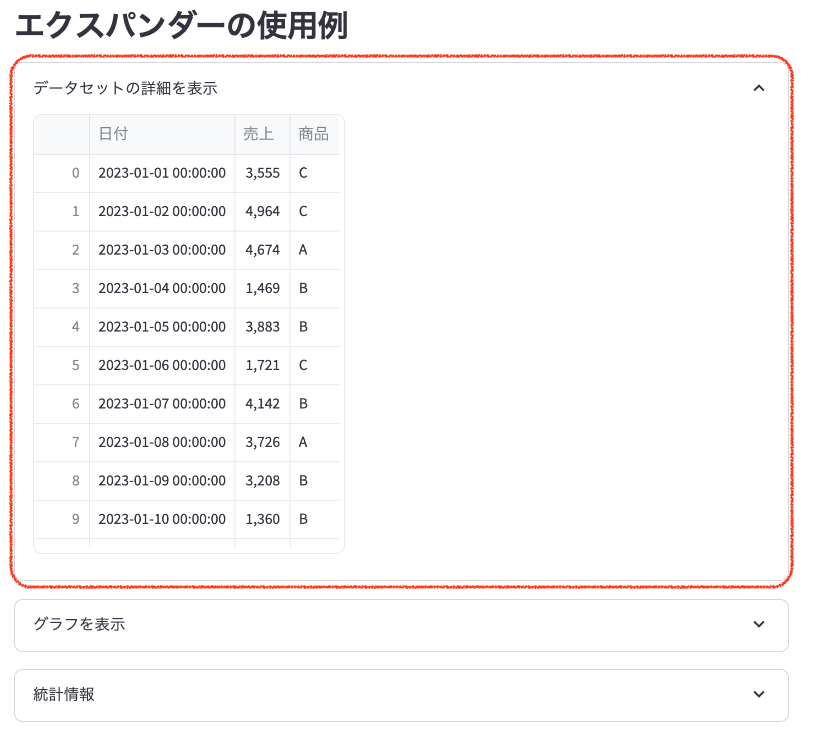
- 「データセットの詳細を表示」エクスパンダー:
クリックすると、売上データの表が表示されます。日付、売上、商品の情報が一目で確認できます。
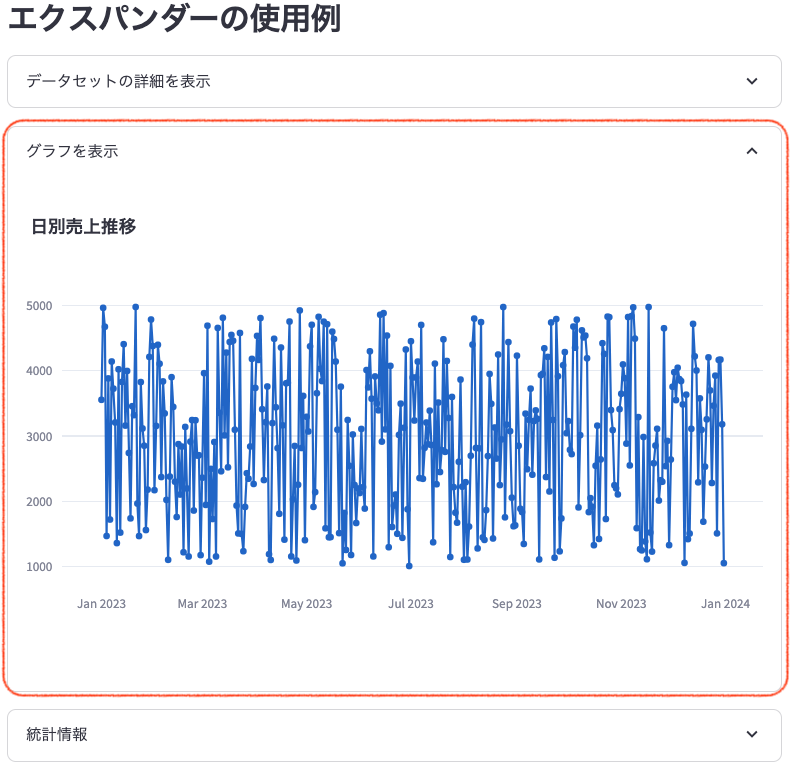
- 「グラフを表示」エクスパンダー:
クリックすると、日別売上推移のグラフが表示されます。x軸が日付、y軸が売上金額を示しています。
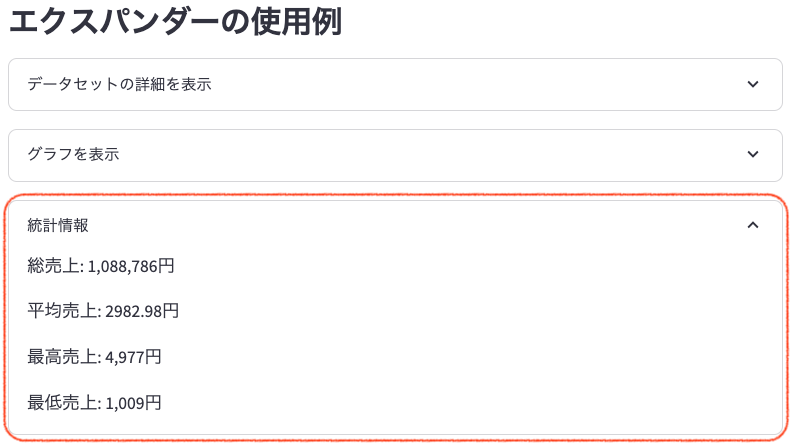
- 「統計情報」エクスパンダー:
クリックすると、総売上、平均売上、最高売上、最低売上などの統計情報が表示されます。
これらのエクスパンダーを使用することで、大量の情報を整理し、必要に応じて表示できるようになっています。
3. サイドバーの基本
サイドバーを使用して、アプリケーションのサイドバーにコントロールや情報を配置します。
st.subheader("サイドバーの使用例")
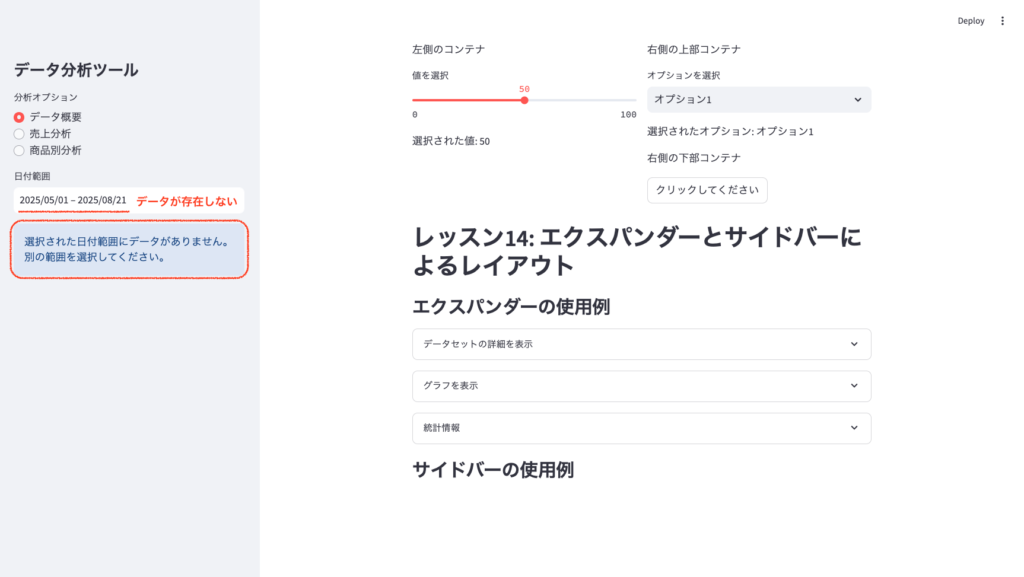
st.sidebar.title("データ分析ツール")
analysis_option = st.sidebar.radio(
"分析オプション",
("データ概要", "売上分析", "商品別分析")
)
date_range = st.sidebar.date_input(
"日付範囲",
value=(sales_data['日付'].min().date(), sales_data['日付'].max().date())
)
filtered_data = sales_data[(sales_data['日付'].dt.date >= date_range[0]) & (sales_data['日付'].dt.date <= date_range[1])]
if filtered_data.empty:
st.sidebar.info("選択された日付範囲にデータがありません。別の範囲を選択してください。")
else:
if analysis_option == "データ概要":
st.write("選択された分析オプション: データ概要")
st.dataframe(filtered_data)
elif analysis_option == "売上分析":
st.write("選択された分析オプション: 売上分析")
st.line_chart(filtered_data.set_index('日付')['売上'])
else:
st.write("選択された分析オプション: 商品別分析")
product_sales = filtered_data.groupby('商品')['売上'].sum().reset_index()
st.bar_chart(product_sales.set_index('商品'))
説明:
st.sidebar: 画面左側にサイドバーを作成します。st.sidebar.title(): サイドバーにタイトルを追加します。st.sidebar.radio(): サイドバーにラジオボタンを作成します。ユーザーに選択肢を提供します。st.sidebar.date_input(): サイドバーに日付選択ウィジェットを作成します。
アプリケーション画面の説明:
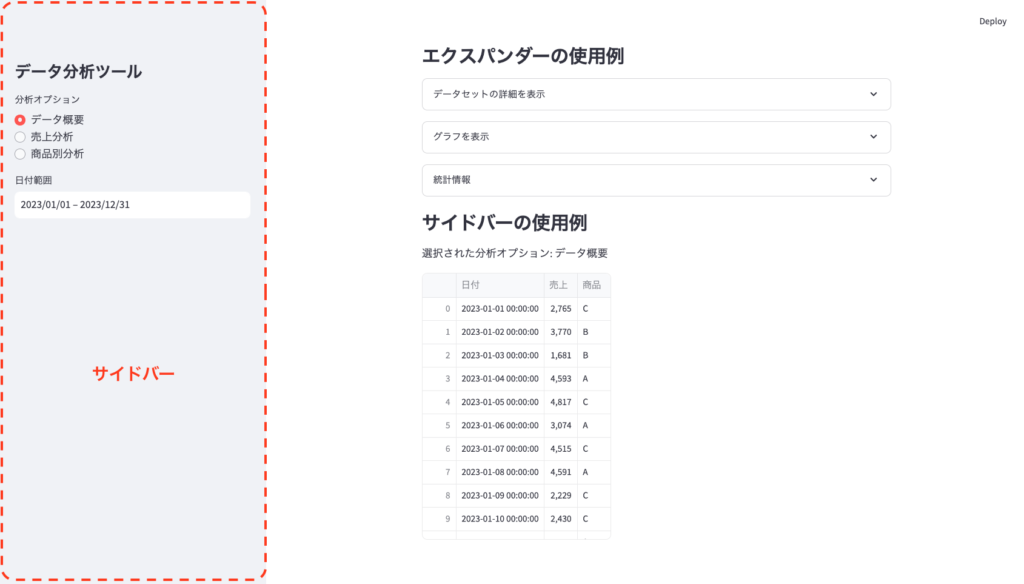
- サイドバー:画面左側に配置されており、「データ分析ツール」というタイトルが表示されています。
- 分析オプション:「データ概要」「売上分析」「商品別分析」の3つのラジオボタンがあります。
- 日付範囲:開始日と終了日を選択できるカレンダーウィジェットがあります。
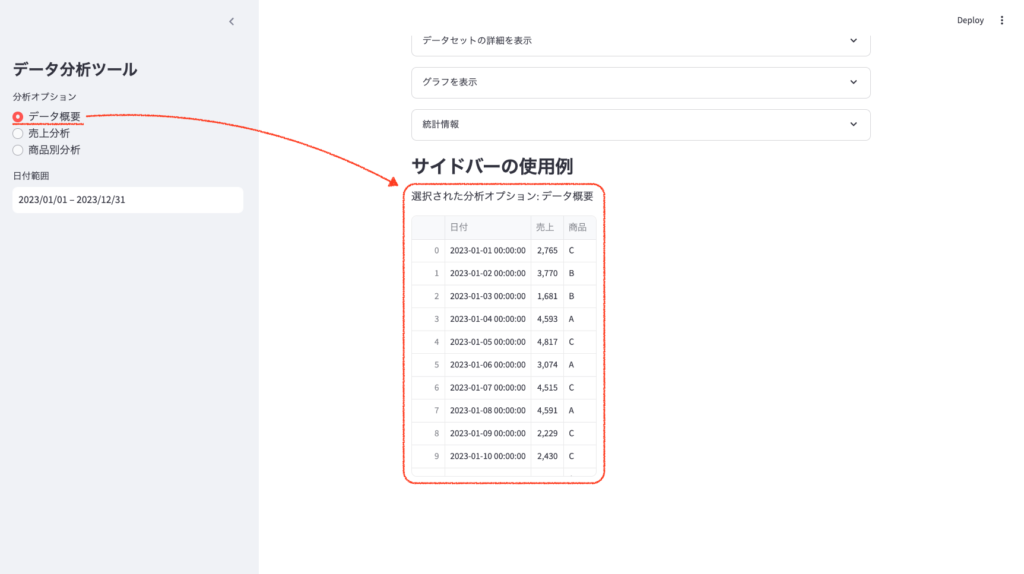
- データ概要:選択すると、メイン画面にデータの表が表示されます。
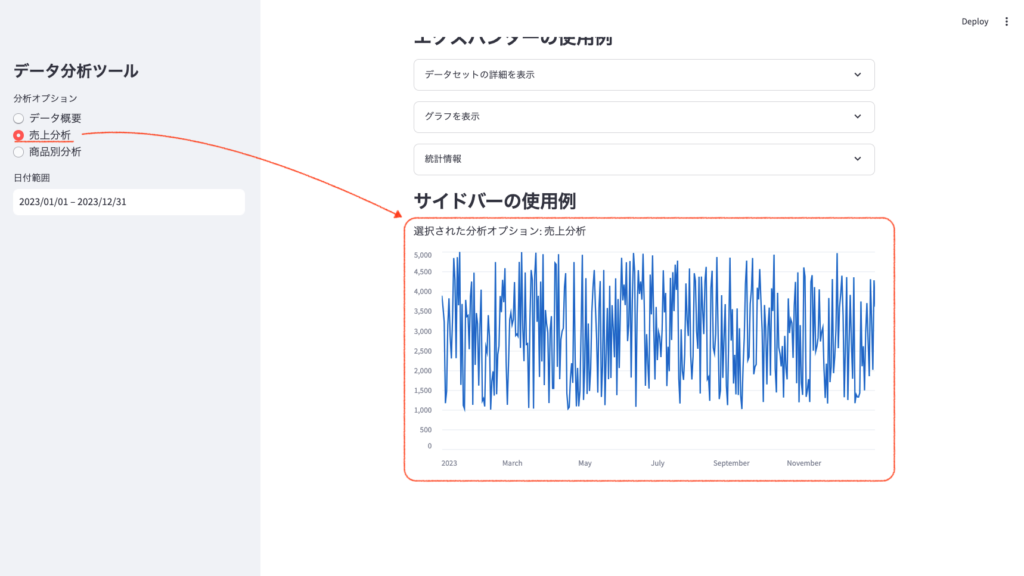
- 売上分析:選択すると、メイン画面に売上の折れ線グラフが表示されます。
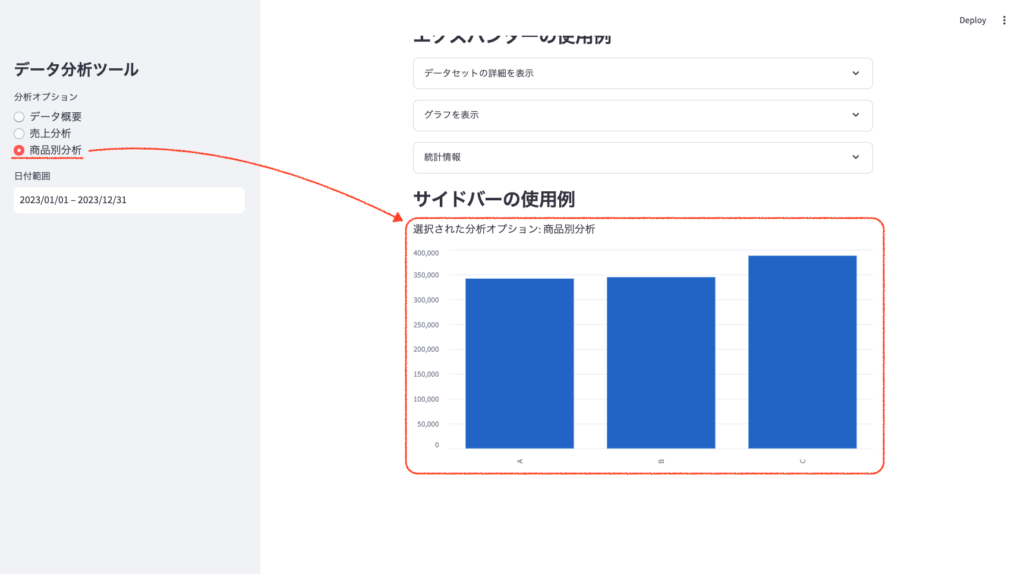
- 商品別分析:選択すると、メイン画面に商品ごとの売上を示す棒グラフが表示されます。
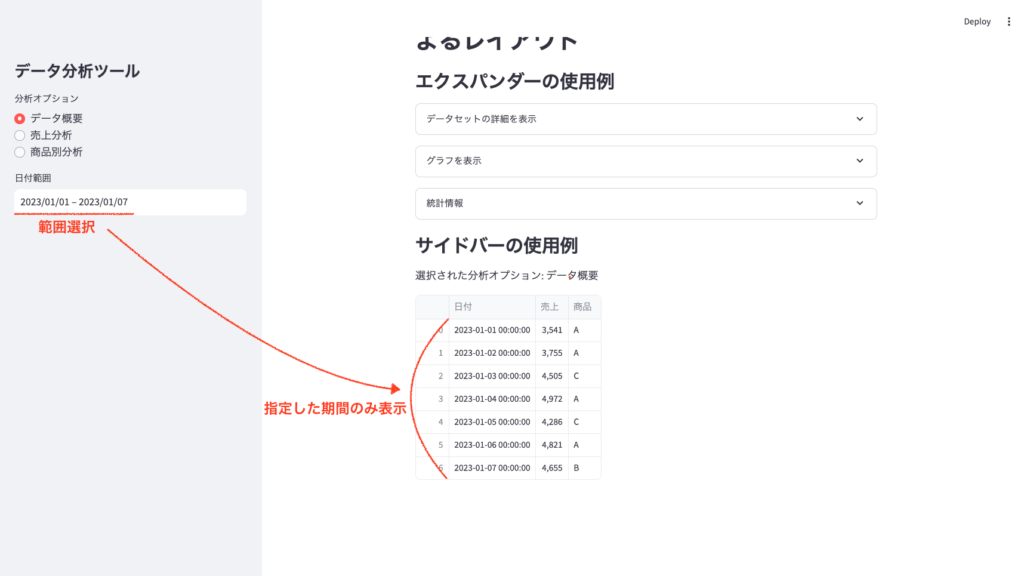
- 日付範囲の指定:サイドバーで特定の日付範囲を選択すると、メイン画面のデータやグラフがその範囲のみに更新されます。
- データがない日付範囲の指定:データが存在しない日付範囲を選択すると、サイドバーに「選択された日付範囲にデータがありません。別の範囲を選択してください。」というメッセージが表示されます。
4. エクスパンダーの高度な使用法
エクスパンダー内にインタラクティブな要素を配置します。
st.subheader("高度なエクスパンダーの使用例")
with st.expander("カスタム分析"):
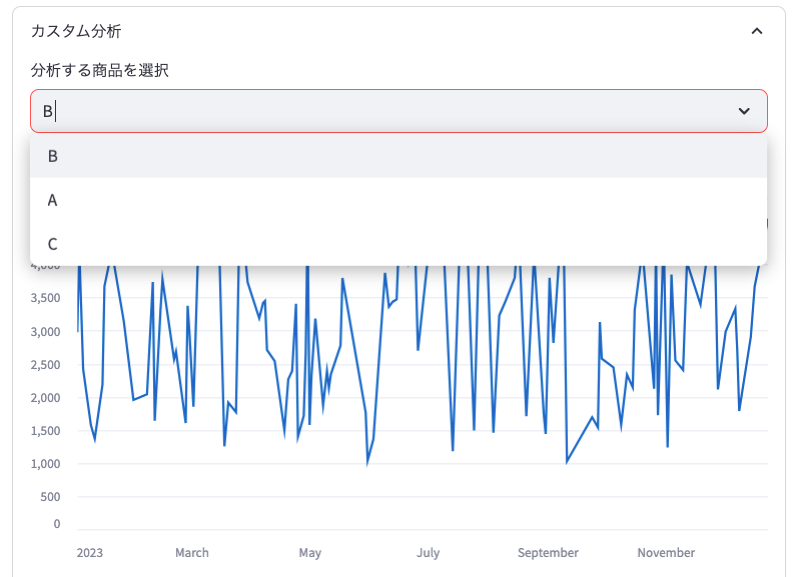
selected_product = st.selectbox("分析する商品を選択", sales_data['商品'].unique())
product_data = filtered_data[filtered_data['商品'] == selected_product]
if product_data.empty:
st.info("選択された日付範囲と商品の組み合わせにデータがありません。")
else:
st.write(f"商品 {selected_product} の分析")
st.line_chart(product_data.set_index('日付')['売上'])
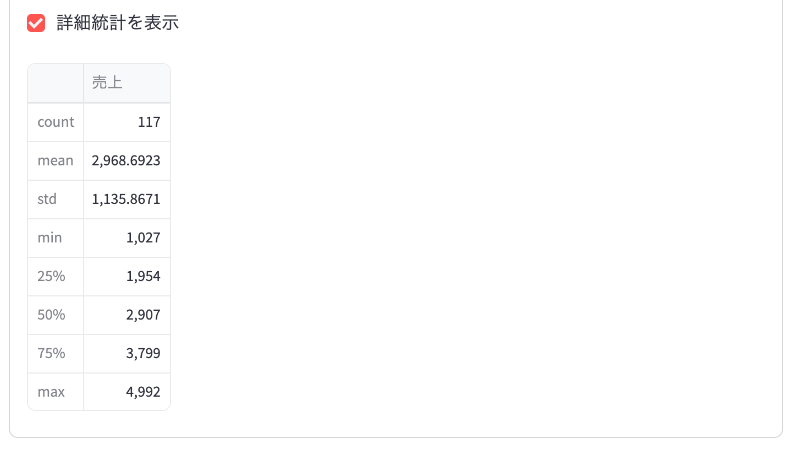
if st.checkbox("詳細統計を表示"):
st.write(product_data['売上'].describe())説明:
- エクスパンダー内に、ドロップダウンメニュー(
st.selectbox)やチェックボックス(st.checkbox)などのインタラクティブな要素を配置できます。 if product_data.empty:: データが存在しない場合のエラーハンドリングを行います。st.info(): 情報メッセージを表示します。st.line_chart(): 選択されたデータの折れ線グラフを表示します。
アプリケーション画面の説明:
- 「カスタム分析」エクスパンダー:クリックすると展開され、詳細な分析オプションが表示されます。
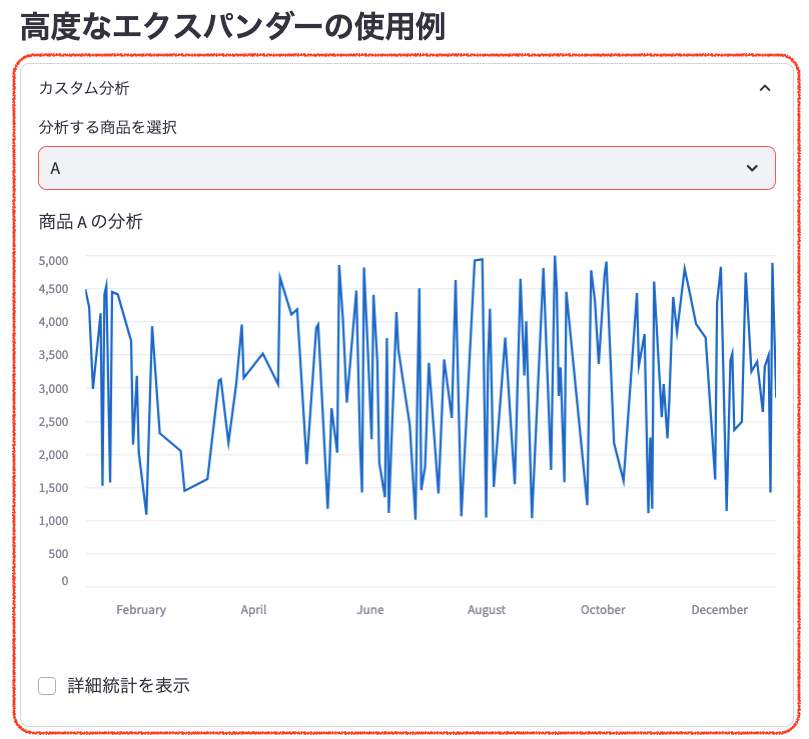
- 商品選択:ドロップダウンメニューから分析したい商品を選択できます。
- 商品別売上グラフ:選択した商品の売上推移を示す折れ線グラフが表示されます。
- 「詳細統計を表示」チェックボックス:これをチェックすると、選択した商品の売上に関する詳細な統計情報(平均、標準偏差、最小値、最大値など)が表示されます。
5. 変更のコミットとプッシュ
- 「ソース管理」パネルで、変更したapp.pyファイルをステージングします。
- コミットメッセージとして「Update expander and sidebar layout with error handling」と入力します。
- 「コミット」ボタンをクリックしてコミットします。
- 「変更の同期」ボタンをクリックして変更をプッシュします。
Step15:Streamlit Cloud アカウント作成
1. Streamlit Cloudとは
Streamlit Cloudは、Streamlitアプリケーションのホスティングサービスです。以下の特徴があります:
- 無料でアプリケーションをホスティングできる
- GitHubと直接連携し、コードの更新を自動的に反映できる
- カスタムドメインの設定が可能
- データ分析や機械学習のプロジェクトを簡単に公開できる
ポートフォリオ作成の観点から見ると、Streamlit Cloudは以下の利点があります:
- プロジェクトを簡単に公開し、共有できる
- インタラクティブなデータ分析アプリケーションをデモンストレーションできる
- 継続的なプロジェクトの更新と改善を示すことができる
2. アカウント作成
Streamlit Cloudのアカウントを作成する手順は以下の通りです:
- ブラウザでStreamlit Cloudにアクセスします。
- 右上の「Sign up」ボタンをクリックします。
- 表示される画面の中央にある「Continue to sign-in」ボタンをクリックします。
- Sign up画面で「Continue with GitHub」を選択します。
- 「Sign in to GitHub to continue to Streamlit Community Cloud」画面が表示されます。
- Username or email addressとPasswordを入力します。
- 「Sign in」ボタンをクリックします。
- 「Authorize Streamlit Community Cloud」画面が表示されます。
- 「Authorize streamlit」ボタンをクリックします。
- 「Verify your email」画面が表示されます。
- メールに届いた確認コードを入力します。
- 再度「Authorize Streamlit」画面が表示されます。
- 「Authorize streamlit」ボタンをクリックします。
- 「Set up your account」画面が表示されます。
- First name(名)とLast name(姓)を入力します。
- Primary email(主要なメールアドレス)を確認または入力します。
- What’s your functional area?(あなたの職種は?)を選択します。
- What stage of app development are you at?(アプリ開発のどの段階ですか?)を選択します。
- Country or region(国または地域)を選択します。
- 「I would like to receive emails…」にチェックを入れると、Streamlitからの情報メールを受け取れます。
- 全て入力したら「Continue」ボタンをクリックします。

これらの手順を完了すると、Streamlit Cloudのアカウントが作成され、ダッシュボードにアクセスできるようになります。
Step16:Streamlit CloudでのGitHubとの連携、デプロイ、セキュリティ設定
1.GitHubとの連携とデプロイ
- Streamlit Cloudのダッシュボードにアクセスします。ログインしていない場合は、「Sign in」をクリックしてログインします。
- ダッシュボード画面で「Create app」ボタンをクリックします。
- 「Do you already have an app?」という画面が表示されます。「Yup, I have an app (Deploy from an app already in a GitHub repo.)」を選択します。
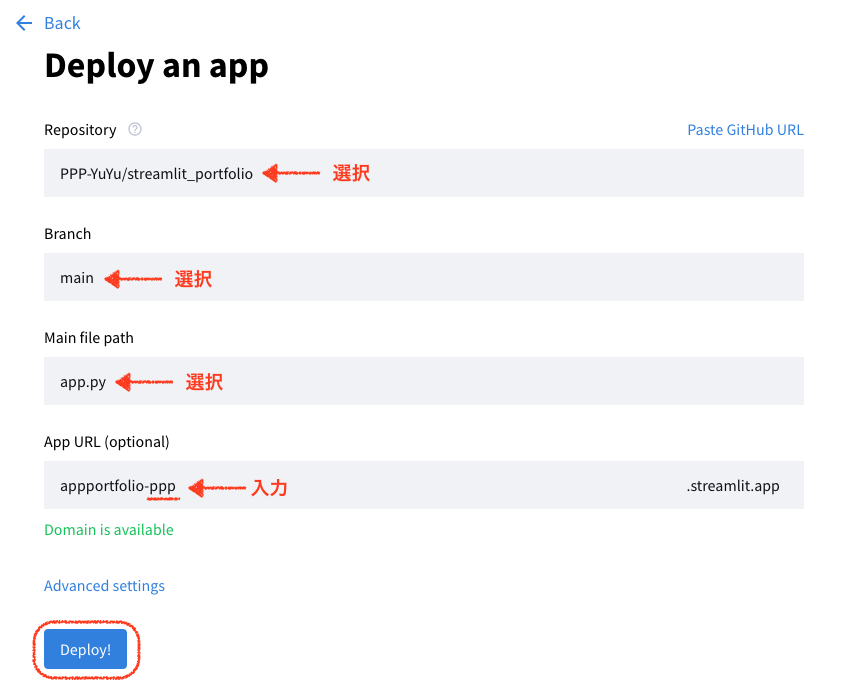
- 「Deploy an app」画面が表示されます。以下の設定を行います:
- Repository: デプロイするリポジトリを選択します。
- Branch: デプロイするブランチを選択します(通常は「main」または「master」)。
- Main file path: アプリの主要なPythonファイルのパスを指定します(通常は「app.py」)。
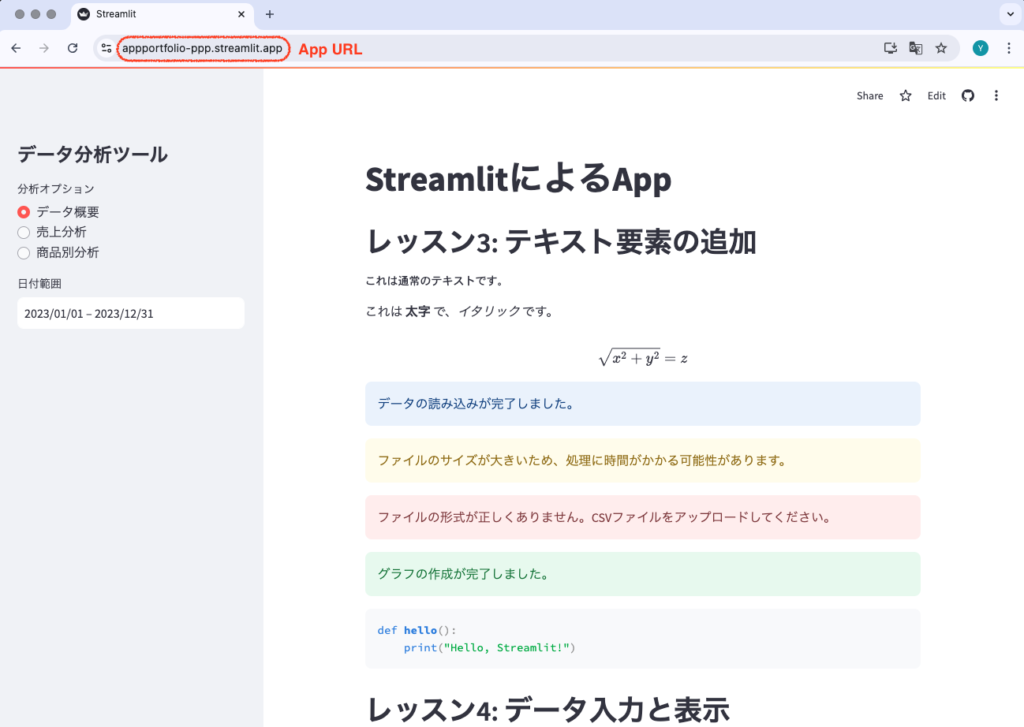
- App URL (optional): アプリのカスタムURLを設定します。形式:appportfolio-入力部.streamlit.app 入力部には、あなたが希望する文字列を入力できます。例:appportfolio-ppp.streamlit.app
- すべての設定が完了したら、「Deploy!」ボタンをクリックします。
- デプロイが開始され、完了すると自動的にApp URLに画面が遷移します。
2. セキュリティ設定
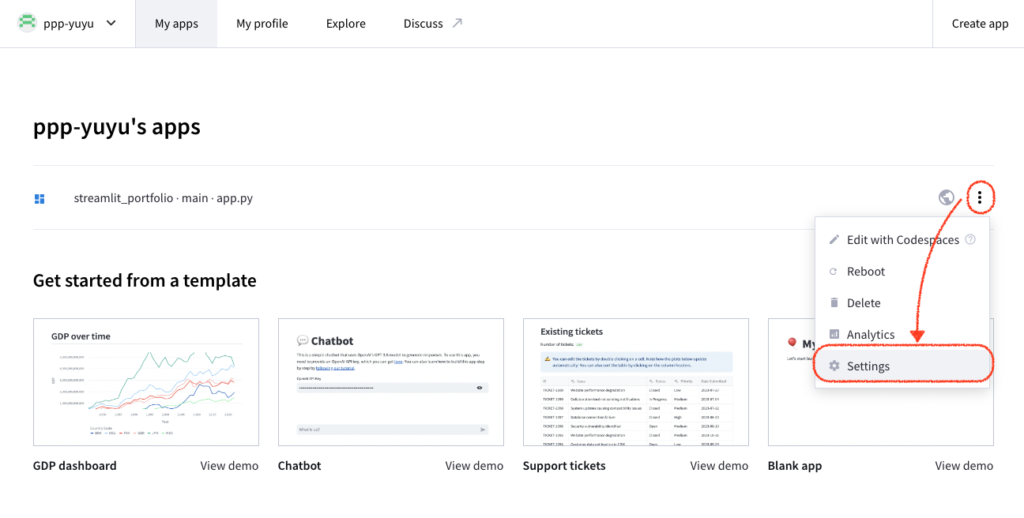
アプリケーションをデプロイした後、以下の手順でセキュリティ設定を行います:
- Streamlit Cloudのダッシュボードで、デプロイしたアプリケーションを選択します。
- アプリケーションの設定ページに移動します。
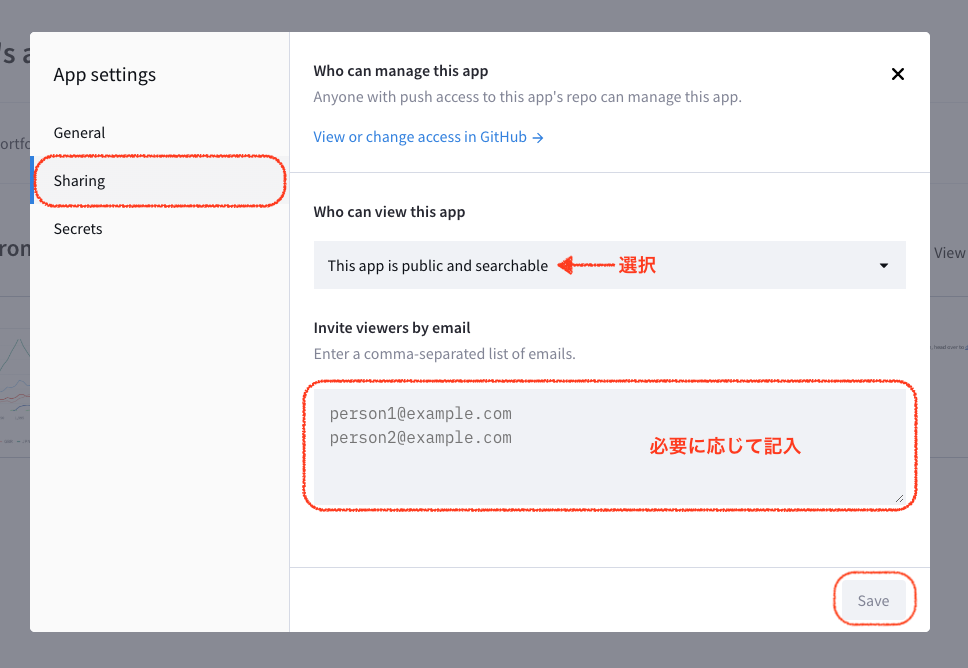
- 「Sharing」セクションを見つけます。
- 「Who can view this app」で以下のオプションから選択します:
- This app is public and searchable: 誰でもアプリにアクセスでき、検索可能になります。
- Only specific people can view this app: 特定のユーザーのみがアクセスできるようになります。
- 「Invite viewers by email」欄は、選択したオプションに関わらず表示されます:
- ここに、特定のユーザーのメールアドレスをカンマ区切りで入力できます。
- 例:user1@example.com, user2@example.com
- 公開アプリの場合でも、ここに入力されたユーザーには特別な通知が送られます。
- 設定を変更したら、ページ下部の「Save」ボタンをクリックして変更を保存します。
3. 動作確認
- デプロイが完了したら、生成されたApp URL(例:appportfolio-ppp.streamlit.app)をブラウザで開きます。
- アプリケーションが正しく表示され、すべての機能が期待通りに動作することを確認します。
- 異なるデバイス(スマートフォン、タブレットなど)やブラウザでもアクセスし、レスポンシブデザインを確認します。
- パブリック設定の場合、別のブラウザやシークレットモードでアクセスし、認証なしでアプリケーションにアクセスできることを確認します。
Step17:Streamlit Cloudアプリケーションのメンテナンスと管理
1. アプリケーションの更新
- VSCodeでアプリケーションを開き、必要な変更を行います。
- VSCodeの「ソース管理」タブを開きます。
- 変更したファイルをステージング領域に追加します。
- コミットメッセージを入力し、「コミット」ボタンをクリックします。
- 「変更の同期」ボタンをクリックしてGitHubリポジトリにプッシュします。
Streamlit Cloudは自動的にGitHubの変更を検知し、新しいバージョンをデプロイします。
2. パフォーマンスの最適化
Streamlitアプリケーションのパフォーマンスを最適化するための方法:
- データの事前処理
- キャッシュの活用
- 非同期処理
- データの分割表示
- 画像の圧縮
- 不要な再計算の防止
3. ユーザーフィードバックの収集と対応
ユーザーフィードバックは、アプリケーションの改善に役立つ重要な情報源です。以下は、フィードバックを収集し対応するための提案です:
- アプリケーション内に簡単な問い合わせフォームへのリンクを追加することを検討してください。
- 定期的にフィードバックを確認し、必要な改善点をリストアップします。
- 重要な更新やメンテナンス情報を、アプリケーションの一部(例:フッター)に表示することを検討してください。
これらの提案は、アプリケーションの機能を大きく変更することなく、ユーザーとのコミュニケーションを改善するためのものです。
4. ドキュメンテーションの更新
プロジェクトのREADME.mdファイルを以下のテンプレートに沿って更新します:
5. ドキュメンテーションの更新
README.mdファイルを最新の状態に保ちます。- アプリケーションの使用方法や機能の説明を、アプリ内で提供します。
- 重要な更新がある場合、変更履歴を維持します。

本コンテンツへの意見や質問